
The Bottom Line: Getting high-quality AI translations requires more than just pasting text into a chat box; you need context-aware prompt engineering, a strict glossary, and scalable infrastructure to process thousands of rows without breaking your data.
Translating your content with Large Language Models (LLMs) offers a massive advantage over traditional machine translation. Instead of blindly swapping words, an LLM can understand the nuances of a sentence and rewrite it exactly how a native speaker would read it.
But to get this level of quality, you cannot simply ask an AI to “translate this.” You need a concrete, repeatable strategy. Here are the precise best practices and prompt techniques to succeed with AI translations.
1. Nail the Prompt Engineering
The biggest benefit of using LLMs for translation is their deep comprehension. Traditional tools translate words one by one. LLMs translate meaning.
To unlock this capability, your prompt must provide the right context and explicit behavioral instructions. If you are translating a short snippet, you must tell the AI the overarching context of the page or the product.
You should explicitly instruct the AI to grasp the exact meaning of the original language first. Once it understands the core message, tell it to temporarily “forget” the exact source words and focus entirely on the destination language. This guarantees that your output will not look like an odd, literal translation.
Here is a concrete prompt snippet you can use to achieve this:
Role: You are an expert, native-speaking translator and copywriter.
Context: You are translating UI text for a B2B SaaS application.
Task:
1. Read the source text to fully understand the underlying meaning and intent.
2. Forget the exact English sentence structure.
3. Rewrite the core meaning in [Target Language] exactly as a native professional would speak.
4. Prioritize absolute fluency and readability over literal, word-for-word translation.By framing the prompt this way, you give the LLM permission to restructure the sentence for maximum naturalness.
2. Enforce a Strict Glossary
Consistency is the foundation of professional localization. You must use a strict glossary to ensure key terms, product names, and industry-specific jargon are always translated in the exact same way.
Ideally, your glossary is prepared by native industry professionals. It should store the specific regulatory phrases or brand names that require exact wording every time they appear. You need to build one distinct glossary per language pair.
Once you have your glossaries, you must provide them to the LLM alongside clear prompt instructions. A common failure point is that glossaries are static, but languages are dynamic. Your glossary will not contain every grammatical variation (singulars, plurals, verb conjugations). With smart prompt engineering, you can instruct the AI to adapt the glossary terms naturally.
Here is an example prompt snippet to enforce a glossary smoothly:
Glossary Rules:
You must strictly use the translations provided in the glossary below.
Crucially, you must adapt these terms to fit the surrounding grammar of the target language. Modify them for plurals, gender, or verb conjugations as required for perfect fluency, but do not change the core root of the term.
Glossary:
- "Dashboard" -> "Tableau de bord"
- "Credit packs" -> "Packs de crédits"
- "Webhooks" -> "Webhooks" (Do not translate)3. Build the Infrastructure for Scalability
For ad hoc, one-off translations, you can use ChatGPT or Claude manually. You write your prompt, paste your text, append the glossary, and copy the result. But when you need to translate content at scale, this manual process breaks down completely.
Imagine having a CSV spreadsheet with thousands of rows and complex language setups. You might have one column for the source content, one column for the target language, and one column for the translated output, which is typical for Weglot CSV exports. Or you might have a single source column and ten different target language columns, like Spanish, Portuguese, and Japanese, that all need to be filled at once.
This becomes highly technical to manage. If you build a naïve automation that feeds all ten target languages and ten different glossaries into a single prompt, the LLM context gets flooded. Providing a Japanese glossary while asking the AI to translate a French column introduces massive noise. It decreases the overall translation quality, confuses the LLM, and drastically increases your token consumption.
If you are a developer, you could build your own automated AI workflows using platforms like n8n, Make, or Zapier. You would need to engineer routing logic to parse the CSV, identify the target language per row, fetch the exact matching glossary, construct the targeted prompt, and push the response back into the correct cell. But for most teams, building and maintaining this infrastructure is a massive distraction.
The AI Glot Advantage
This is why we recommend specialized tools like AI Glot. AI Glot handles all the complex prompt engineering, glossary routing, and infrastructure behind the scenes.
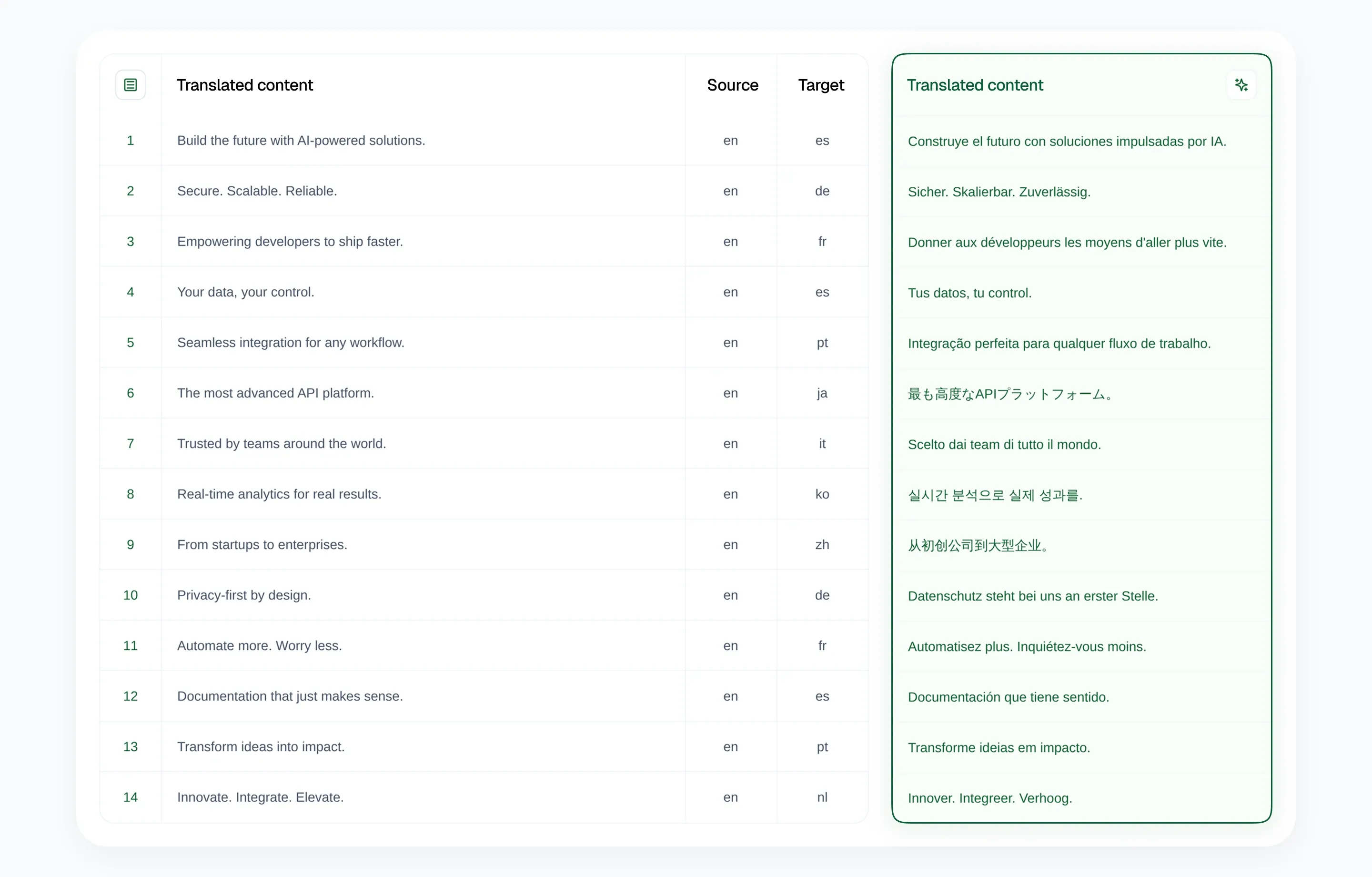
AI Glot allows you to easily store your glossaries in distinct Workspaces. You simply upload your CSV, select the translation setup you want to apply, and confirm the smart mapping of your different columns. The platform automatically injects the right context, routes the exact glossary for that specific language pair, and applies the optimal translation prompt.
The process is incredibly fast. In recent tests, 1,500 rows were translated in less than a minute.
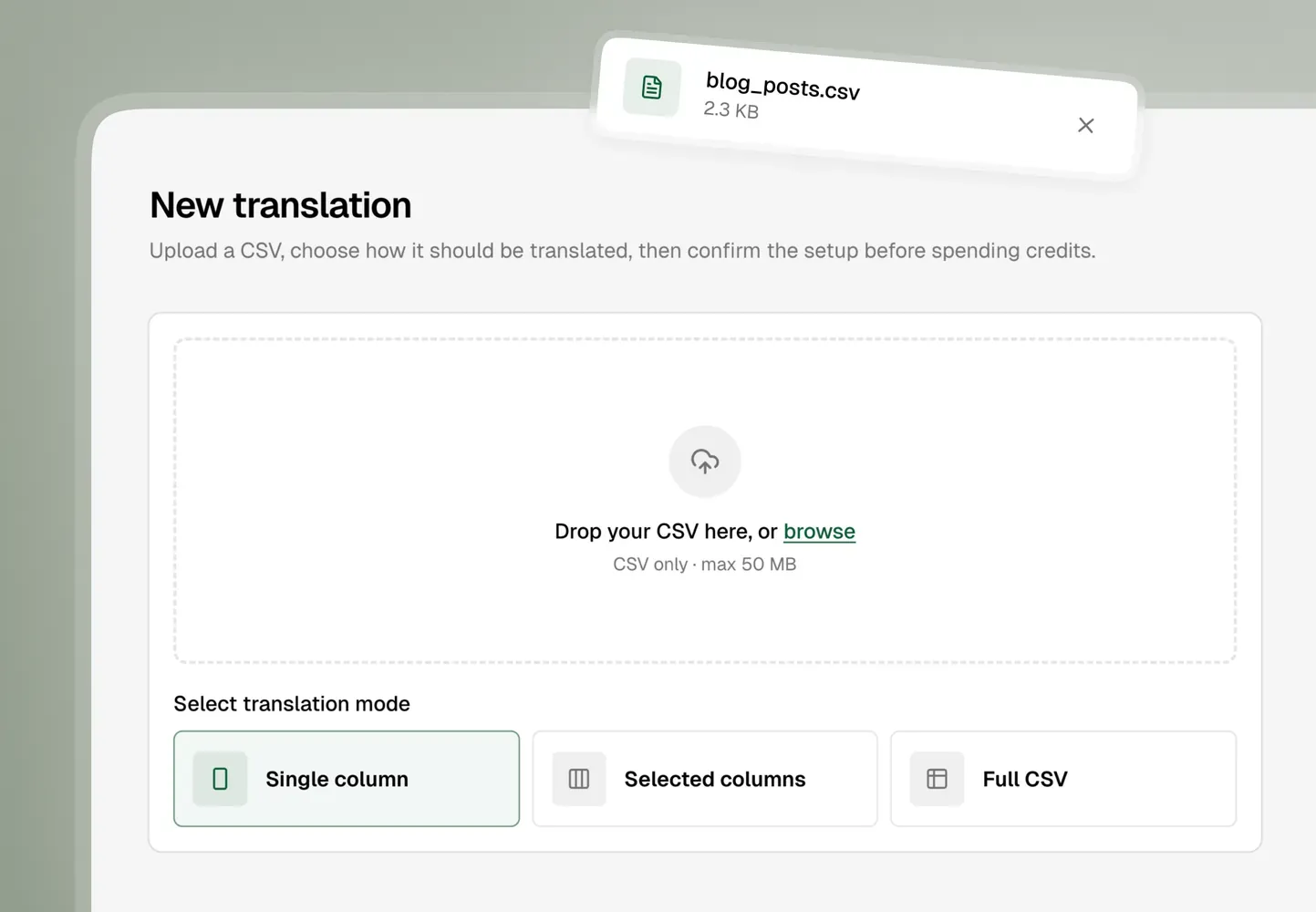
Instead of spending hours copying and pasting, or weeks building complex n8n automation workflows, you get a clean, properly structured file ready for immediate import. By combining context-aware prompting, strict glossary management, and purpose-built infrastructure, you guarantee high-quality AI translations every single time.

