
In sintesi: un sito Astro multilingue è un problema strutturale prima ancora di essere un problema di traduzione. Imposta cartelle di contenuto pulite per ogni locale, estrai ogni blocco traducibile in un unico CSV, traducilo in Multi-language Columns mode, quindi riassembla i file a livello di codice. Una volta impostata la pipeline, aggiungere una nuova lingua diventa un’operazione da un singolo file CSV.
Questo è esattamente il flusso di lavoro che utilizziamo per mantenere ai-glot.com in sei lingue (inglese, francese, tedesco, spagnolo, italiano, portoghese) senza riscrivere a mano un singolo post del blog. Lo analizzeremo dall’inizio alla fine, includendo i prompt che usiamo per strutturare ogni passaggio con un assistente alla codifica AI come Claude Code o Cursor.
L’obiettivo
Al termine di questa guida avrai:
- Una struttura di routing i18n pulita nel tuo progetto Astro, con una cartella per lingua.
- Uno script ripetibile che estrae ogni stringa traducibile da un file markdown (o da un’esportazione CMS) in un unico file CSV.
- Un CSV tradotto prodotto in AI Glot utilizzando la modalità Multi-language Columns.
- Un secondo script che riassembla i file markdown tradotti, con i percorsi delle immagini e i link interni corretti per le sottodirectory localizzate.
- Un file “skill” da consegnare al tuo assistente AI, affinché ogni nuovo articolo sia traducibile per impostazione predefinita.
Se utilizzi già Weglot, Crowdin o un CMS headless che esporta in CSV, puoi saltare lo script di estrazione markdown e caricare direttamente quelle esportazioni su AI Glot. La logica di traduzione e riassemblaggio rimane la stessa.
Prerequisiti
Una breve checklist prima di iniziare.
- Un progetto Astro (v4 o v5) in esecuzione locale, con le Content Collections configurate per il blog.
- Node 20 o superiore, in modo che le moderne API per CSV e
fs/promisesfunzionino correttamente. - Uno workspace AI Glot (il piano gratuito è sufficiente per il primo blocco).
- Un assistente AI nel tuo editor per generare il boilerplate (Claude Code, Cursor, Copilot, Codeium, a tua scelta).
Perché Astro è ideale per il multilingue su larga scala
Astro esegue il rendering in HTML statico per impostazione predefinita, il che significa che ogni pagina localizzata è semplicemente un file sul disco. Non c’è alcun layer di traduzione runtime, nessuna ricerca di database per il selettore di lingua, nessun bundle JavaScript da scaricare per ogni locale. Google indicizza ogni versione linguistica come un URL distinto con i propri meta tag, e l’output della build è essenzialmente uno specchio tradotto del tuo ramo inglese.
Questo è esattamente ciò che serve per la SEO. La SEO multilingue funziona meglio quando ogni lingua ha la propria pagina scansionabile e generata staticamente, con le corrette annotazioni hreflang e una struttura URL pulita. Astro ti offre tutto questo gratuitamente.
Il compromesso: sei tu il responsabile del mantenimento dei contenuti sincronizzati tra le varie lingue. Questo è precisamente il problema che la pipeline CSV descritta di seguito risolve.
Parte 1: Configurare la struttura di routing i18n
Astro 4 ha introdotto una configurazione i18n di primo livello. Il pattern più pulito consiste nel dichiarare i locale, impostare il default senza prefisso (così l’inglese risiede in /blog/my-post e il francese in /fr/blog/my-post) e rispecchiare le content collection in una cartella [lang]/ per lingua.
Ecco una struttura di destinazione per un blog con sei lingue:
src/
content/
blog/
live/ # English (default locale)
my-first-post.md
fr/live/ # French
my-first-post.md
de/live/ # German
my-first-post.md
es/live/ # Spanish
my-first-post.md
it/live/ # Italian
my-first-post.md
pt/live/ # Portuguese
my-first-post.md
pages/
blog/[slug].astro # English routes
[lang]/blog/[slug].astro # Localized routes
i18n/
ui.ts # UI string dictionary per localeNota che i file markdown localizzati si trovano in una cartella più profonda rispetto a quelli inglesi. Questa profondità è importante: i percorsi relativi delle immagini nel markdown localizzato necessitano di un ../ extra per raggiungere src/assets/. Lo script di riassemblaggio nella Parte 4 gestisce questo aspetto automaticamente.
Se preferisci non scrivere manualmente questa ossatura, consegna il seguente prompt al tuo assistente AI. È intenzionalmente generico in modo da funzionare su qualsiasi progetto Astro e pone le giuste domande di chiarimento prima di generare il codice.
You are helping me scaffold internationalization (i18n) in an existing Astro
project. I want to translate my entire site into multiple languages while
keeping clean URLs, proper hreflang annotations, and per-locale static pages.
Obiettivi:
1. Dichiarare i locale in astro.config.mjs usando l'opzione integrata `i18n`.
Il locale predefinito NON deve avere prefissi (es. l'inglese risiede in `/blog/...`,
il francese in `/fr/blog/...`).
2. Creare una struttura di cartelle per locale per le mie content collection, in modo che ogni
post del blog (o elemento del CMS) abbia un file corrispondente 1:1 per lingua. I file inglesi
rimangono nella loro posizione attuale; i file localizzati risiedono in una cartella più profonda
(es. `src/content/blog/fr/live/`).
3. Aggiungere un dizionario tipizzato per le stringhe UI in `src/i18n/ui.ts` che esporti un oggetto
con chiavi per lingua, più un helper `useTranslations(lang)`.
4. Aggiornare lo schema della content collection in modo che la stessa definizione Zod si applichi a
ogni cartella di lingua.
5. Generare il file per le rotte dinamiche `src/pages/[lang]/blog/[slug].astro` che
legga dalla content collection localizzata e torni all'inglese (fallback) quando
manca una versione localizzata.
6. Aggiungere un componente `<LanguageSwitcher />` che renderizzi un link per ogni lingua,
mantenendo il pathname corrente.
7. Inserire i tag `<link rel="alternate" hreflang="..." />` nel layout per
ogni lingua che ha la pagina disponibile.
Prima di generare qualsiasi codice, chiedimi:
- L'elenco delle lingue di destinazione (codici BCP 47) e quella predefinita.
- Il percorso delle mie content collection esistenti e dei file di rotta attuali.
- Se desidero un selettore di lingua nell'header, nel footer o in entrambi.
- Se attualmente memorizzo le stringhe UI in JSON, TS o in altro modo.
Quindi apporta le modifiche con commit piccoli e chirurgici. Non rifattorizzare codice
non correlato. Mostrami il diff e spiega ogni decisione in cui esistono due pattern validi
(es. prefisso vs. nessun prefisso per la lingua di default).Questo pattern è intenzionale: chiarire, poi costruire. Abbiamo provato inizialmente l’approccio “genera tutto subito” e ci siamo ritrovati con tre diversi componenti per il cambio lingua e uno schema di routing che andava in conflitto con lo schema della content collection. Chiedere all’assistente di interrogarti prima ti farà risparmiare un’ora di pulizia dopo.
Parte 2: Estrarre i contenuti in un CSV per la traduzione
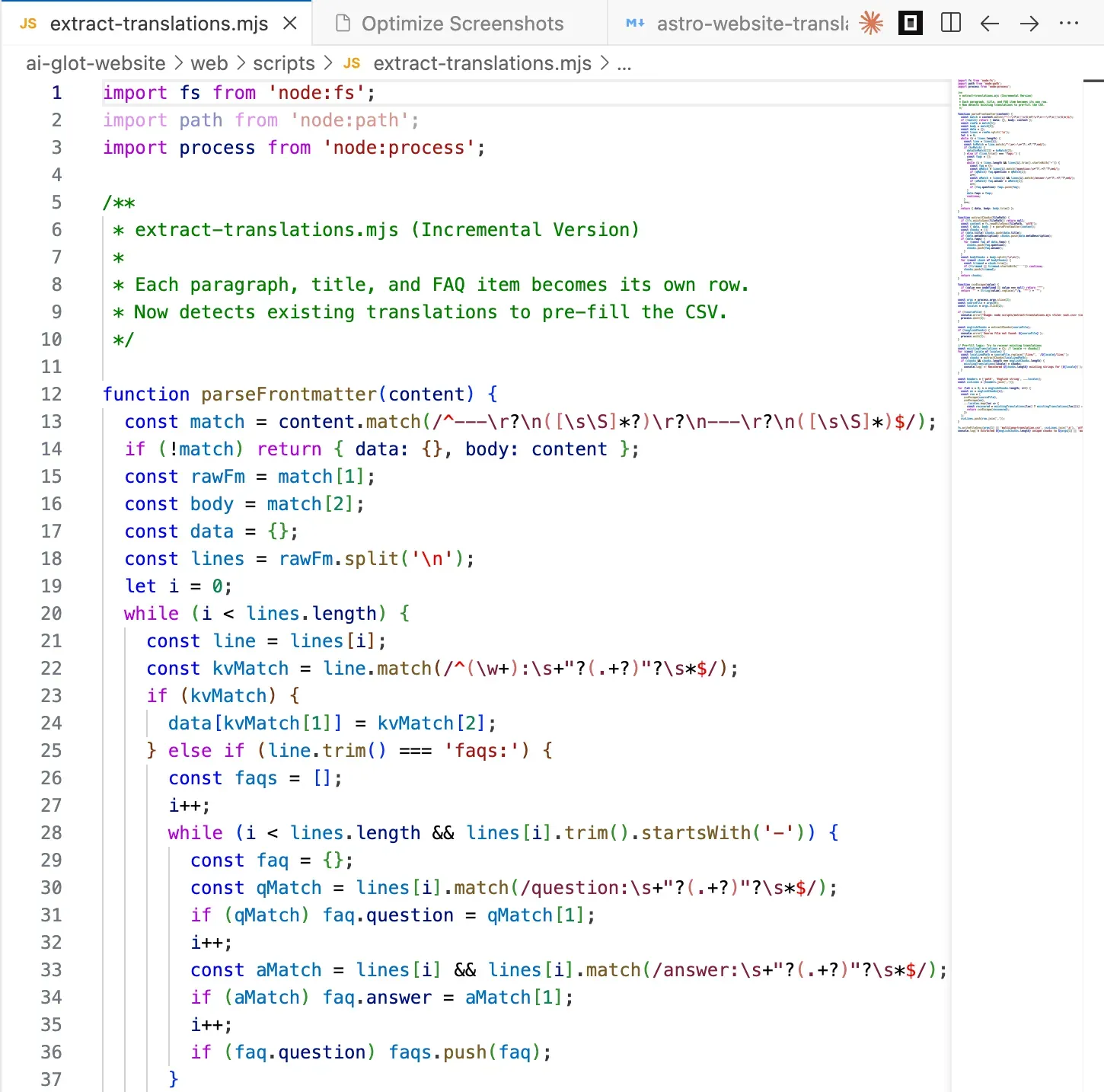
È qui che la maggior parte dei team si blocca.
È qui che la maggior parte dei team si blocca. La traduzione in sé è la parte facile. Portare i contenuti dentro e fuori da uno strumento di traduzione senza rompere la struttura è la parte difficile.
Il trucco che fa brillare la modalità Multi-language Columns di AI Glot è l’estrazione a blocchi (chunked). Suddividi ogni file markdown nelle unità traducibili più piccole dotate di senso (un campo frontmatter, una coppia FAQ, un singolo paragrafo), inserisci ogni blocco come una riga in un CSV e aggiungi una colonna per ogni lingua di destinazione. Il risultato appare così:
| path | English string | fr | de | es | it | pt |
|---|---|---|---|---|---|---|
| live/my-first-post.md | Come tradurre un sito Astro su larga scala in molte lingue | |||||
| live/my-first-post.md | Un tutorial pratico, copia-e-incolla, per lanciare un sito Astro multilingue. | |||||
| live/my-first-post.md | Astro renderizza HTML statico per impostazione predefinita, il che significa che ogni pagina localizzata è semplicemente un file sul disco. |
Perché a blocchi (chunk)? Perché la traduzione AI funziona molto meglio su unità coerenti della dimensione di un paragrafo rispetto a interi documenti. Le regole del glossario vengono applicate in modo coerente. Il budget dei token rimane prevedibile. E se un blocco necessita di una correzione, modifichi una singola cella, non un file da 2.000 parole.
Opzione A: I contenuti sono salvati come file markdown (blog, documentazione, landing page)
Usa questo prompt per generare uno script di estrazione personalizzato per la tua repository. Ne usiamo una versione quasi identica per il sito web di AI Glot.
Write a Node.js script at `scripts/extract-translations.mjs` that prepares a
CSV for bulk translation in AI Glot.
Input:
- Una cartella sorgente contenente i file markdown in inglese
(es. `src/content/blog/live/`).
- L'elenco dei codici lingua di destinazione (es. `fr de es it pt`).
- Il percorso di un CSV di output (predefinito `multilang-translation.csv`).
Per ogni file markdown:
1. Analizza il frontmatter usando `gray-matter`.
2. Estrai queste stringhe traducibili, una per riga CSV:
- `title` (frontmatter)
- `metaDescription` (frontmatter)
- Per ogni voce in `faqs`: la `question` e la `answer` come righe separate.
- Ogni paragrafo del corpo del testo, dividendo il markdown su `\n\n` in modo che paragrafi,
elenchi puntati, citazioni (blockquotes) e intestazioni diventino ciascuno una riga.
3. SALTA questi blocchi (non includerli nel CSV):
- Righe contenenti solo immagini che iniziano con `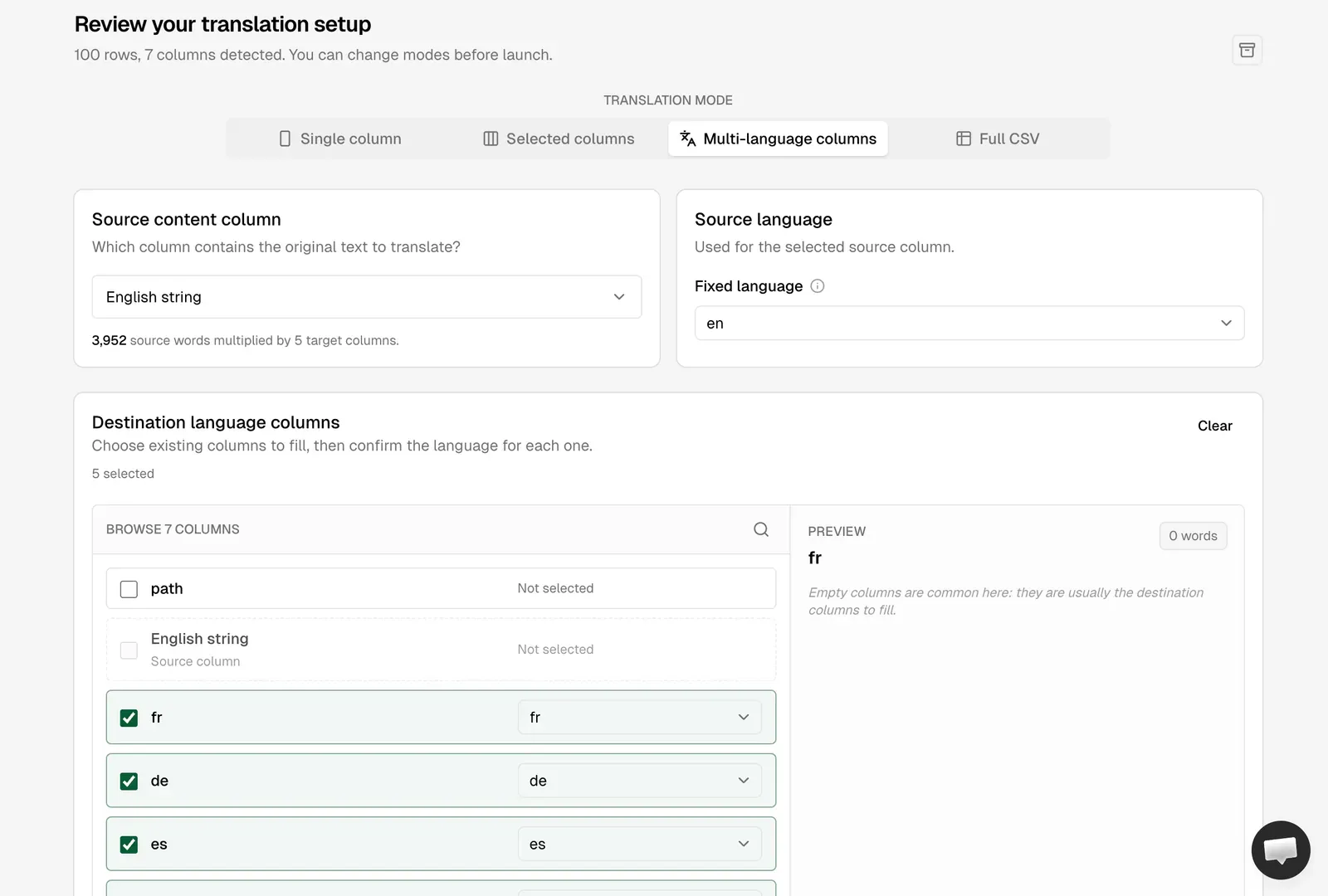
Un blog di 30 post con cinque lingue di destinazione viene in genere elaborato in pochi minuti in modalità Standard, e puoi passare alla modalità Pro per un output di qualità superiore sulle righe più importanti (titoli, meta description, paragrafi hero).
Suggerimento: una volta caricato il file su AI Glot, puoi eliminare la versione locale con le colonne vuote. Il tuo workspace diventerà la fonte di verità da quel momento in poi, e potrai scaricarlo in qualsiasi momento.
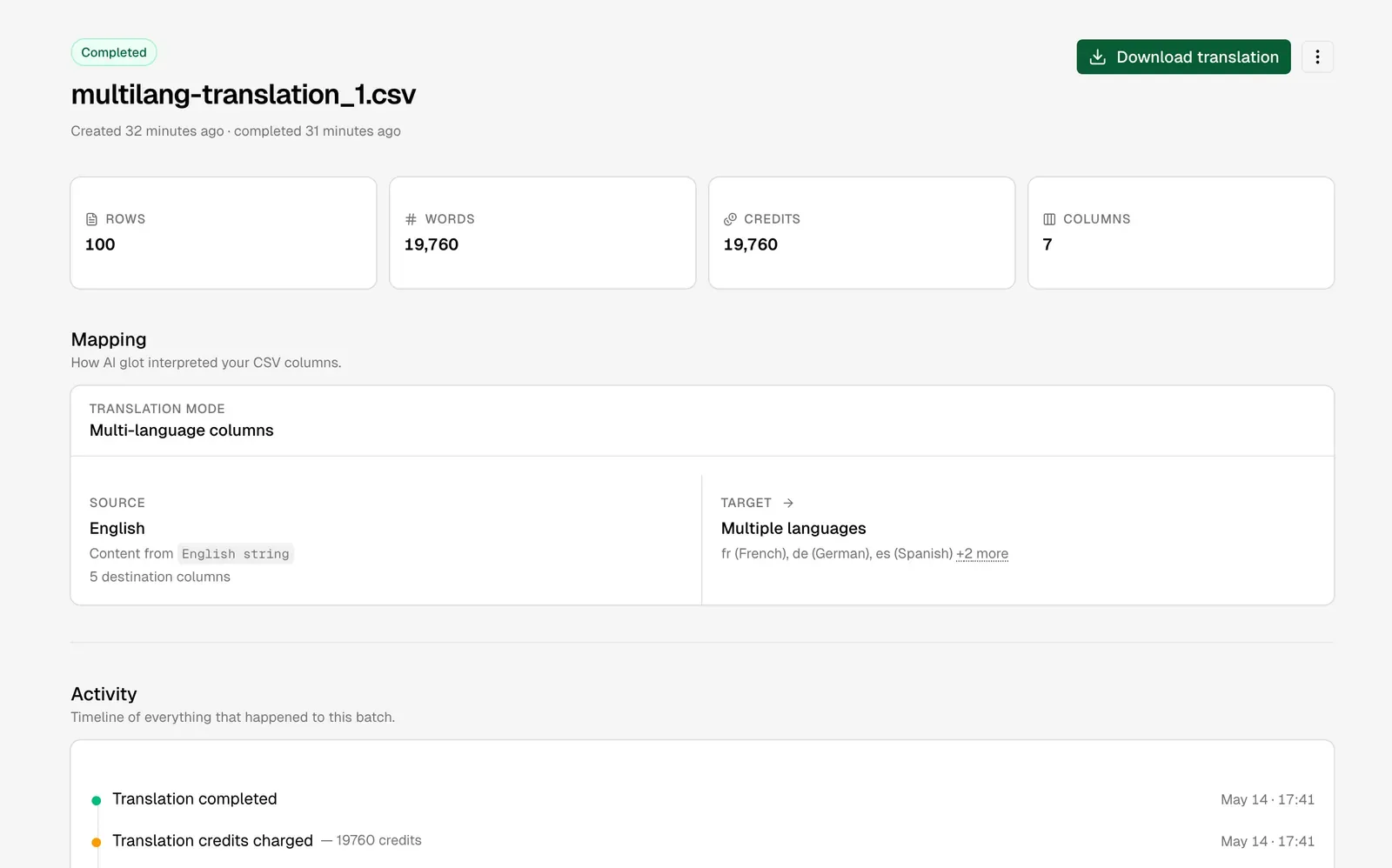
Parte 4: Riassemblare il markdown tradotto in Astro
Ora hai un file multilang-translation_translated.csv con ogni colonna di destinazione compilata. Il compito è prendere ogni blocco tradotto e scriverlo nel file markdown localizzato corretto, preservando esattamente la struttura originale.
È qui che l’estrazione a blocchi si rivela nuovamente vantaggiosa. Poiché ogni riga è identificata dal blocco originale in inglese, puoi semplicemente trovare e sostituire i blocchi inglesi con la loro controparte localizzata all’interno del file sorgente originale, quindi salvare il risultato nella cartella localizzata. Nessun parsing AST, nessuna conversione markdown avanti e indietro, nessun rischio di rompere la formattazione.
Durante la ricostruzione devono essere effettuate due correzioni strutturali:
- Percorsi delle immagini. I file inglesi fanno riferimento agli asset con
../../../../assets/.... I file localizzati si trovano in una cartella più profonda, quindi il percorso relativo diventa../../../../../assets/.... - Link interni. Un link come
/blog/glossary-website-translationsin inglese deve diventare/it/blog/glossary-website-translationsin italiano (e così via per ogni lingua).
Ecco il prompt che usiamo per generare lo script di riassemblaggio. È abbastanza generico da essere inserito in qualsiasi progetto Astro che segua la struttura della Parte 1.
Use the unified assembly script at `scripts/assemble-blog-translations.mjs` that rebuilds
localized markdown files from an AI Glot Multi-language Columns CSV.
Input (argomenti CLI):
- Percorso del CSV tradotto (es. `multilang-translation_translated.csv`)
con le colonne `path, English string, fr, de, es, it, pt`.
- La cartella sorgente contenente i file markdown inglesi originali
(predefinita `src/content/blog/live/`).
- Il pattern della cartella di destinazione per i file localizzati
(predefinita `src/content/blog/{lang}/live/`).
- L'origine del sito utilizzata per i link interni (predefinita `https://ai-glot.com`).
Per ogni valore univoco di `path` nel CSV:
1. Leggi il file originale in inglese da `<sourceDir>/<path>`.
2. Per ogni colonna della lingua di destinazione (tutto ciò che segue `English string`):
a. Parti dal testo completo del file inglese.
b. Per ogni riga che corrisponde a questo `path`, trova la `English string`
esatta nel file e sostituiscila con il valore nella colonna della
lingua di destinazione. Usa una sostituzione di stringa letterale, non regex.
Interrompi con errore se il blocco inglese non viene trovato (significa che
la sorgente è cambiata rispetto al CSV; è meglio un errore esplicito che
un'omissione silenziosa).
c. Dopo tutte le sostituzioni, esegui due correzioni strutturali sul testo risultante:
- Percorsi immagini: sostituisci ogni occorrenza di `../../../../assets/` con
`../../../../../assets/` (un `../` extra perché i file localizzati risiedono
un livello più sotto).
- Link interni: sostituisci ogni URL interno assoluto su questo sito
(es. `https://ai-glot.com/blog/...`) e ogni percorso relativo alla root
(es. `/blog/...`, `/sign-up`) con l'equivalente prefissato dalla lingua
(`/it/blog/...`, `/it/sign-up`). Salta le ancore (`#...`), gli URL esterni
e i link `mailto:` o `tel:`.
d. Scrivi il file in `<destDir risolto con questa lingua>/<path>`. Crea le
cartelle se necessario.
3. Dopo aver elaborato tutti i percorsi, stampa un riepilogo: file scritti per lingua,
sostituzioni totali, eventuali blocchi che non è stato possibile trovare.
Robustezza:
- Usa `papaparse` per leggere il CSV. Rimuovi il BOM se presente.
- Mantieni l'esatta formattazione del frontmatter (delimitatori, ordine delle chiavi, virgolette).
Il modo più semplice è operare tramite sostituzioni sulla stringa grezza del file, non su un
AST parsato.
- Sii idempotente: eseguire lo script due volte sugli stessi input deve produrre gli
stessi output.
Crea un unico file indipendente. Utilizzo:
`node scripts/assemble-blog-translations.mjs translated.csv`Esegui lo script e vedrai apparire una pioggia di nuovi file sotto src/content/blog/fr/live/, src/content/blog/de/live/ e così via. Fai un controllo a campione su uno, lancia astro dev e le tue rotte localizzate dovrebbero essere renderizzate all’istante.

Bonus 1: Un file “skill” per rendere ogni nuovo articolo “traducibile per impostazione predefinita”
Una volta che la pipeline funziona, vorrai che ogni articolo futuro segua lo stesso flusso. Il trucco: salva queste convenzioni come un file “skill” che il tuo assistente IA leggerà prima di scrivere qualsiasi nuovo post.
Se usi Claude Code, Cursor o qualsiasi editor IA che carichi istruzioni a livello di progetto, inserisci questo file nel tuo repo come skills/blog_translation_workflow.md. Utilizziamo esattamente questo schema qui a AI Glot.
---
name: blog_translation_workflow
description: How to ship a new blog post so it can be translated in bulk later.
---
# Pipeline di traduzione del blog
Quando scrivi un nuovo post o un elemento del CMS, segui queste convenzioni affinché
scorra agevolmente attraverso la pipeline di estrazione multilingue.
## 1. Posizione e nomenclatura dei file
- Le bozze si trovano in `src/content/blog/draft/`.
- Slug = nome del file = la stessa stringa usata nel frontmatter `slug:`.
- Sposta in `src/content/blog/live/` solo dopo la revisione.
## 2. Requisiti del frontmatter
Ogni post DEVE avere:
- `title`: sentence case, senza punto finale.
- `metaDescription`: da 140 a 160 caratteri, frase completa.
- `coverImage`: percorso relativo dalla posizione di questo file.
- `publishedDate`: data in formato ISO.
- `slug`: corrispondente al nome del file.
- `faqs`: array di `{ question, answer }`. Minimo 3 elementi.
## 3. Struttura del corpo del testo per una traduzione ottimale
- Usa titoli in sentence-case (niente Title Case).
- Mantieni i paragrafi tra 1 e 4 frasi. Ogni paragrafo diventa una riga del CSV,
quindi paragrafi brevi si traducono in modo più affidabile.
- Non inserire mai due immagini di seguito; separale sempre con almeno un
paragrafo di testo esplicativo.
- I link interni usano percorsi relativi alla root (`/blog/...`, `/sign-up`).
- I percorsi delle immagini usano `../../../../assets/...` (profondità della versione inglese).
## 4. Dopo la pubblicazione
Esegui:
```bash
node scripts/extract-translations.mjs src/content/blog/live/<slug>.md \
multilang-translation.csv fr de es it pt
```
per aggiungere i blocchi traducibili di questo articolo al CSV principale. Carica il
CSV su AI Glot in modalità Multi-language Columns, quindi esegui:
```bash
node scripts/assemble-blog-translations.mjs multilang-translation_translated.csv
```
per generare i file markdown localizzati.
## 5. Anti-pattern (Errori da evitare)
- NON usare le lineette (em-dash); usa virgole o due punti.
- NON formattare in grassetto interi paragrafi. Evidenzia solo le frasi chiave.
- NON saltare la sezione FAQ; le FAQ sono i blocchi con il maggior impatto SEO.
- NON inserire HTML grezzo nel markdown se non strettamente necessario;
complica la riassemblaggio basato sui blocchi.La prossima volta che tu (o chiunque nel tuo team) scriverete un nuovo articolo, l’assistente leggerà prima questo file e produrrà un post adatto alla pipeline senza bisogno di pulizie manuali.
Bonus 2: Aggiungere una nuova lingua a tutto il blog in un unico passaggio
Questa è la parte che sorprende di più le persone. Una volta creata la pipeline, aggiungere una nuova lingua è un’operazione che richiede un solo CSV per l’intero archivio del blog.
Supponiamo che tu abbia 80 articoli tradotti in francese, tedesco, spagnolo, italiano e portoghese e decida di aggiungere l’olandese.
Il flusso di lavoro:
- Riesegui lo script di estrazione aggiungendo
nlalla lista delle lingue. Poiché lo script legge dalla cartella sorgente inglese, ogni articolo (vecchio e nuovo) verrà incluso. - Apri il CSV. La colonna
English stringè identica alla volta precedente. Le colonnefr, de, es, it, ptrimangono vuote (lo script non guarda le traduzioni esistenti; costruisce solo la matrice vuota). La colonnanlè nuova e vuota. - Rimuovi le colonne che non devi ritradurre. Elimina
fr, de, es, it, ptdal foglio di calcolo, mantienipath, English string, nl. - Carica su AI Glot ed esegui la modalità Multi-language Columns con
nlcome unico target. - Esegui lo script di riassemblaggio con il nuovo CSV. Questo scriverà ogni articolo in
src/content/blog/nl/live/.
Sei passato da “dobbiamo aggiungere l’olandese” a “l’olandese è online” con un solo caricamento. Per 80 articoli. Ecco cosa succede quando è il workflow a lavorare, non il team.
Lo stesso schema funziona per modifiche puntuali: modifica un singolo paragrafo in inglese, esporta nuovamente solo i blocchi interessati, traducili e ricompila. Gli aggiornamenti rimangono economici perché la pipeline è strutturale, non basata sui documenti.
Checklist di verifica
Prima di andare in produzione, fai un controllo di integrità per ogni lingua:
npm run build(oastro build) deve completarsi senza erroriImageNotFound.- Passa il mouse sul selettore di lingua in un post localizzato e conferma che l’URL rimanga pulito.
- Apri un post in francese e fai un controllo a campione: titolo, meta description, primi tre paragrafi, una risposta FAQ. Confrontali con l’originale.
- Clicca su un link interno nel post francese. Dovrebbe portarti a un’altra pagina in francese, non tornare all’inglese.
- Ispeziona l’
<head>per le corrette annotazionihreflangtra tutte le lingue. - Esegui un audit Lighthouse su un URL localizzato; il punteggio SEO dovrebbe essere identico all’equivalente inglese.
Se uno di questi passaggi fallisce, i colpevoli più comuni sono: profondità del percorso immagine errata, un link interno sfuggito alla regex o un blocco che ha subito variazioni tra l’estrazione e il riassemblaggio. Gli avvisi “could not find chunk” dello script di riassemblaggio ti indicheranno esattamente dove guardare.
Considerazioni finali
Un sito Astro multilingue su larga scala non è un progetto di traduzione. È una pipeline di contenuti. Se imposti correttamente la pipeline (routing delle lingue, estrazione CSV a blocchi, traduzione con AI Glot, riassemblaggio deterministico), tradurre un nuovo articolo, correggere un paragrafo o aggiungere una nuova lingua diventa un’operazione di routine invece di un’iniziativa trimestrale.
Gli elementi che lo rendono possibile:
- Il supporto i18n nativo di Astro per pagine statiche pulite per ogni lingua.
- Un piccolo script di estrazione che trasforma il markdown in un CSV traducibile.
- La modalità Multi-language Columns di AI Glot per completare ogni lingua in un unico passaggio, con controllo su glossario e istruzioni.
- Uno script di riassemblaggio che gestisce la profondità delle immagini e la localizzazione dei link interni.
- Un file skill affinché ogni nuovo articolo sia compatibile con la pipeline per impostazione predefinita.
Pronto a lanciare il multilingue? Crea il tuo workspace su AI Glot, carica il tuo primo CSV di estrazione e guarda il tuo blog andare online in sei lingue entro la fine del pomeriggio.


