
Fazit: Eine mehrsprachige Astro-Website ist zuerst ein strukturelles Problem, bevor es zu einem Übersetzungsproblem wird. Richten Sie saubere Inhaltsordner pro Locale ein, extrahieren Sie jeden übersetzbaren Block in eine einzige CSV, übersetzen Sie diese im Modus für mehrsprachige Spalten und setzen Sie die Dateien programmatisch wieder zusammen. Sobald die Pipeline steht, ist das Hinzufügen einer neuen Sprache nur noch ein einziger CSV-Vorgang.
Dies ist exakt der Workflow, den wir verwenden, um ai-glot.com in sechs Sprachen (Englisch, Französisch, Deutsch, Spanisch, Italienisch, Portugiesisch) zu pflegen, ohne einen einzigen Blog-Post manuell neu zu schreiben. Wir gehen ihn Schritt für Schritt durch – inklusive der Prompts, mit denen wir jeden Schritt mit einem KI-Coding-Assistenten wie Claude Code oder Cursor aufbauen.
Das Ziel
Am Ende dieses Guides verfügen Sie über:
- Eine saubere i18n-Routing-Struktur in Ihrem Astro-Projekt mit einem Ordner pro Sprache.
- Ein wiederverwendbares Skript, das jeden übersetzbaren String aus einer Markdown-Datei (oder einem CMS-Export) in eine einzige CSV extrahiert.
- Eine übersetzte CSV, erstellt in AI Glot im Modus für mehrsprachige Spalten.
- Ein zweites Skript, das die übersetzten Markdown-Dateien wieder zusammenfügt, wobei Bildpfade und interne Links für die lokalisierten Unterverzeichnisse korrigiert werden.
- Eine Skill-Datei für Ihren KI-Assistenten, damit jeder neue Artikel standardmäßig übersetzbar ausgeliefert wird.
Wenn Sie bereits Weglot, Crowdin oder ein Headless CMS verwenden, das CSV exportiert, können Sie das Markdown-Extraktionsskript überspringen und diese Exporte direkt in AI Glot einspeisen. Die Logik für Übersetzung und Zusammenführung bleibt identisch.
Voraussetzungen
Eine kurze Checkliste, bevor Sie starten.
- Ein Astro-Projekt (v4 oder v5), das lokal läuft, mit Content Collections für Ihren Blog.
- Node 20 oder höher, damit die modernen CSV- und
fs/promises-APIs reibungslos funktionieren. - Ein AI Glot Workspace (der kostenlose Tarif reicht für den ersten Schwung).
- Ein KI-Assistent in Ihrem Editor für die Code-Generierung (Claude Code, Cursor, Copilot, Codeium – was Sie bevorzugen).
Warum Astro ideal für skalierbare Mehrsprachigkeit ist
Astro rendert standardmäßig statisches HTML, was bedeutet, dass jede lokalisierte Seite einfach eine Datei auf dem Datenträger ist. Es gibt keine Laufzeit-Übersetzungsschicht, keine Datenbankabfragen für Sprachwechsler und kein JavaScript-Bundle, das pro Sprache zusätzlich heruntergeladen werden muss. Google indexiert jede Sprachversion als eine eigene URL mit eigenen Meta-Tags, und das Build-Ergebnis ist im Grunde ein übersetztes Spiegelbild Ihrer englischen Struktur.
Genau das ist ideal für SEO. Mehrsprachiges SEO funktioniert am besten, wenn jede Sprache ihre eigene crawlbare, statisch generierte Seite hat – inklusive korrekter hreflang-Tags und sauberer URL-Struktur. Astro liefert Ihnen das von Haus aus.
Der einzige Kompromiss: Sie sind dafür verantwortlich, dass die Content-Dateien über alle Sprachen hinweg synchron bleiben. Genau dieses Problem löst die unten beschriebene CSV-Pipeline.
Teil 1: Einrichten der i18n-Routing-Struktur
Astro 4 hat eine erstklassige i18n-Konfiguration eingeführt. Das sauberste Pattern ist, die Locales zu deklarieren, den Standardwert auf „kein Präfix“ zu setzen (sodass Englisch unter /blog/mein-post und Französisch unter /fr/blog/mein-post liegt) und Ihre Content Collections in einen [lang]/-Ordner pro Sprache zu spiegeln.
Hier ist eine Zielstruktur für einen Blog mit sechs Sprachen:
src/
content/
blog/
live/ # English (default locale)
my-first-post.md
fr/live/ # French
my-first-post.md
de/live/ # German
my-first-post.md
es/live/ # Spanish
my-first-post.md
it/live/ # Italian
my-first-post.md
pt/live/ # Portuguese
my-first-post.md
pages/
blog/[slug].astro # English routes
[lang]/blog/[slug].astro # Localized routes
i18n/
ui.ts # UI string dictionary per localeBeachten Sie, dass die lokalisierten Markdown-Dateien eine Ebene tiefer liegen als die englischen. Diese Tiefe ist wichtig: Relative Bildpfade in lokalisiertem Markdown benötigen ein zusätzliches ../, um src/assets/ zu erreichen. Das Zusammenführungsskript in Teil 4 erledigt dies automatisch.
Wenn Sie dieses Grundgerüst nicht selbst schreiben möchten, geben Sie den folgenden Prompt an Ihren KI-Coding-Assistenten. Er ist absichtlich allgemein gehalten, damit er für jedes Astro-Projekt funktioniert, und stellt die richtigen klärenden Fragen, bevor er Code generiert.
You are helping me scaffold internationalization (i18n) in an existing Astro
project. I want to translate my entire site into multiple languages while
keeping clean URLs, proper hreflang annotations, and per-locale static pages.
Ziele:
1. Deklariere Locales in astro.config.mjs mit der integrierten `i18n`-Option.
Die Standard-Sprache soll KEIN Präfix erhalten (z. B. Englisch unter `/blog/...`,
Französisch unter `/fr/blog/...`).
2. Erstelle eine Ordnerstruktur pro Locale für meine Content Collections, sodass jeder
Blogpost (oder CMS-Eintrag) eine 1:1-Datei pro Sprache hat. Die englischen Dateien
bleiben an ihrem jetzigen Ort; lokalisierte Dateien liegen einen Ordner tiefer
(z. B. `src/content/blog/fr/live/`).
3. Füge ein typisiertes UI-String-Dictionary unter `src/i18n/ui.ts` hinzu, das ein nach
Sprachen gegliedertes Objekt sowie einen `useTranslations(lang)`-Helper exportiert.
4. Aktualisiere das Content Collection Schema, sodass dieselbe Zod-Definition für
jeden Sprachordner gilt.
5. Generiere die dynamische Route `src/pages/[lang]/blog/[slug].astro`, die aus der
lokalisierten Content Collection liest und auf Englisch zurückfällt, wenn eine
lokalisierte Version fehlt.
6. Füge eine `<LanguageSwitcher />` Komponente hinzu, die einen Link pro Sprache
rendert und den aktuellen Pfad beibehält.
7. Injiziere `<link rel="alternate" hreflang="..." />` Tags in das Layout für jede
Sprache, für die die Seite verfügbar ist.
Bevor du Code generierst, frage mich nach:
- Der Liste der Ziel-Locales (BCP 47 Codes) und welche die Standard-Sprache ist.
- Dem Pfad zu meinen vorhandenen Content Collections und aktuellen Route-Dateien.
- Ob ich den Sprachwechsler im Header, Footer oder in beiden möchte.
- Ob ich UI-Strings aktuell in JSON, TS oder anderswo speichere.
Führe die Änderungen dann in kleinen, präzisen Commits durch. Refaktoriere keinen
unbeteiligten Code. Zeige mir den Diff und erkläre Entscheidungen, wo es zwei valide
Ansätze gibt (z. B. Präfix vs. kein Präfix für die Standard-Sprache).Dieses Vorgehen ist Absicht: erst klären, dann bauen. Wir haben anfangs den „Generiere einfach alles“-Ansatz ausprobiert und endeten mit drei verschiedenen Sprachwechsler-Komponenten und einem Routing-Schema, das mit unserem Content Collection Schema kollidierte. Den Assistenten anzuweisen, zuerst Rückfragen zu stellen, spart später eine Stunde Aufräumarbeit.
Teil 2: Inhalte in eine Übersetzungs-CSV extrahieren
Hier bleiben die meisten Teams stecken. Die Übersetzung selbst ist der einfache Teil. Den Inhalt in ein Übersetzungstool hinein und wieder herauszubekommen, ohne die Struktur zu zerstören, ist die Herausforderung.
Der Trick, der den Modus für mehrsprachige Spalten von AI Glot so effektiv macht, ist die segmentierte Extraktion. Sie unterteilen jede Markdown-Datei in die kleinsten sinnvollen übersetzbaren Einheiten (ein Frontmatter-Feld, ein FAQ-Paar, ein einzelner Absatz), schreiben jedes Segment als eine Zeile in eine CSV und fügen pro Zielsprache eine Spalte hinzu. Das Ergebnis sieht so aus:
This is where most teams get stuck. The translation itself is the easy part. Getting your content into and out of a translation tool without breaking structure is the hard part.
The trick that makes AI Glot’s Multi-language Columns mode shine is chunked extraction. You split each markdown file into the smallest meaningful translatable units (a frontmatter field, an FAQ pair, a single paragraph), write each chunk as one row in a CSV, and add one column per target language. The result looks like this:
| path | English string | fr | de | es | it | pt |
|---|---|---|---|---|---|---|
| live/my-first-post.md | How to translate an Astro website at scale into many languages | |||||
| live/my-first-post.md | A practical, copy-paste tutorial for shipping a multilingual Astro site. | |||||
| live/my-first-post.md | Astro renders static HTML by default, which means each localized page is just a file on disk. |

Warum Chunks?
Warum häppchenweise? Weil KI-Übersetzungen bei zusammenhängenden Einheiten in Absatzgröße weitaus besser funktionieren als bei ganzen Dokumenten. Glossar-Regeln werden konsistent angewendet. Das Token-Budget bleibt vorhersehbar. Und falls ein Abschnitt korrigiert werden muss, bearbeiten Sie eine einzelne Zelle statt einer Datei mit 2.000 Wörtern.
Option A: Sie speichern Inhalte als Markdown-Dateien (Blog, Dokumentationen, Landingpages)
Verwenden Sie diesen Prompt, um ein Extraktionsskript zu erstellen, das genau auf Ihr Repository zugeschnitten ist. Eine nahezu identische Version nutzen wir auch für die AI-Glot-Website.
Write a Node.js script at `scripts/extract-translations.mjs` that prepares a
CSV for bulk translation in AI Glot.
Inputs:
- Ein Quellverzeichnis mit englischen Markdown-Dateien
(z. B. `src/content/blog/live/`).
- Eine Liste der Ziel-Sprachcodes (z. B. `fr de es it pt`).
- Ein Pfad für die CSV-Ausgabe (Standard: `multilang-translation.csv`).
Für jede Markdown-Datei:
1. Parsen des Frontmatters mit `gray-matter`.
2. Extrahieren dieser übersetzbaren Strings (eine pro CSV-Zeile):
- `title` (Frontmatter)
- `metaDescription` (Frontmatter)
- Für jeden Eintrag in `faqs`: `question` und `answer` als separate Zeilen.
- Jeder Absatz im Fließtext, wobei der Markdown-Body bei `\n\n` getrennt wird, sodass Absätze,
Aufzählungslisten, Blockzitate und Überschriften jeweils eine Zeile bilden.
3. Diese Abschnitte ÜBERSPRINGEN (nicht in die CSV aufnehmen):
- Reine Bild-Zeilen, die mit `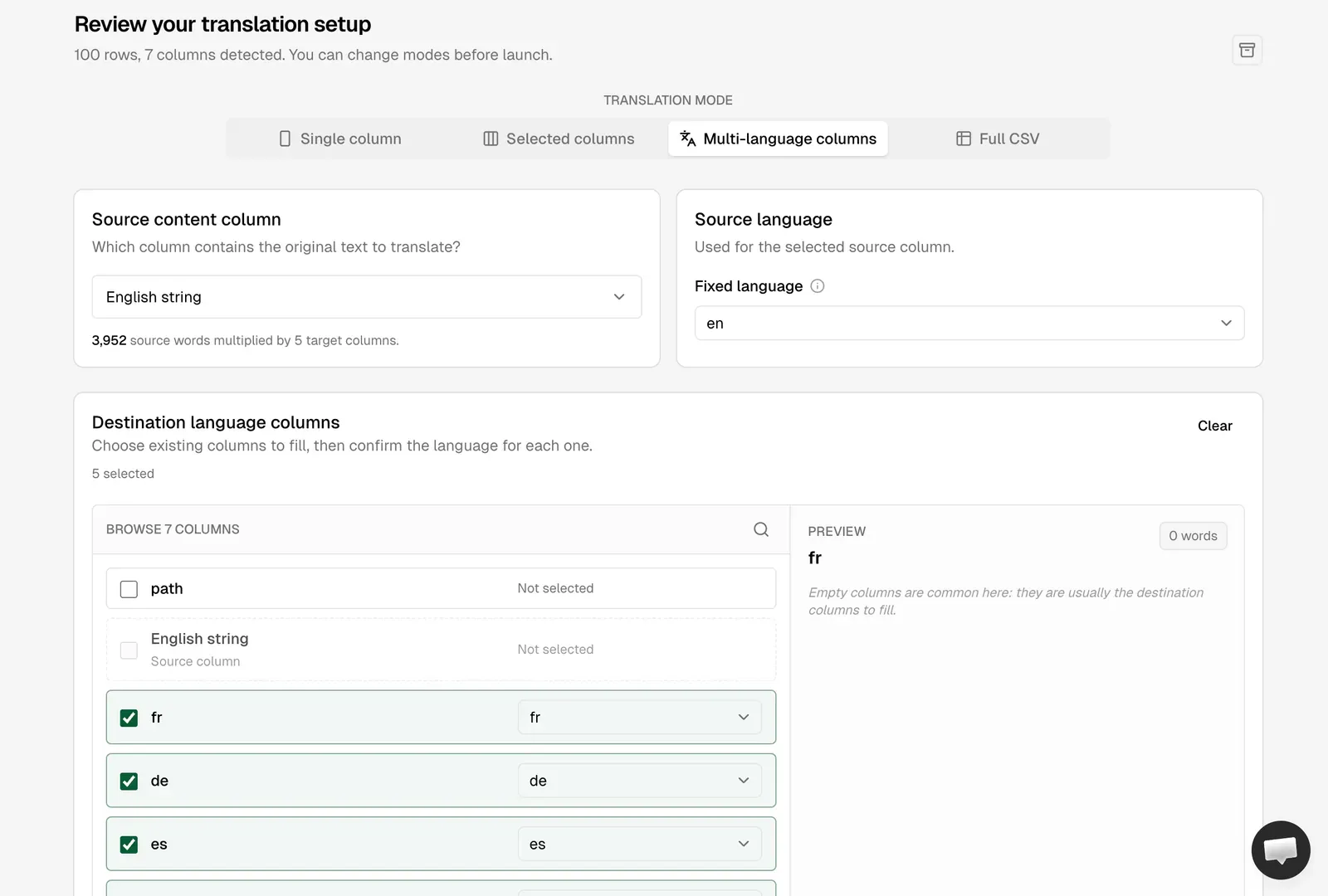
Ein Blog mit 30 Posts
Ein Blog mit 30 Posts und fünf Zielsprachen wird im Standard-Modus typischerweise in wenigen Minuten verarbeitet. Für besonders wichtige Zeilen (Titel, Meta-Beschreibungen, Hero-Absätze) können Sie in den Pro-Modus wechseln, um eine noch höhere Qualität zu erzielen.
Tipp: Sobald die Datei bei AI Glot hochgeladen ist, können Sie die lokale Version mit den leeren Spalten löschen. Ihr Workspace ist von nun an die „Source of Truth“, und Sie können die Datei jederzeit wieder herunterladen.
Teil 4: Zusammenbau der übersetzten Markdown-Dateien für Astro
Nun liegt Ihnen eine multilang-translation_translated.csv vor, in der jede Zielspalte gefüllt ist. Die Aufgabe besteht darin, jeden übersetzten Abschnitt zurück in die richtige lokalisierte Markdown-Datei zu schreiben und dabei die ursprüngliche Struktur exakt beizubehalten.
Hier zahlt sich die häppchenweise Extraktion erneut aus. Da jede Zeile über den englischen Originaltext referenziert wird, können Sie einfach die englischen Textabschnitte innerhalb der Quelldatei suchen und durch ihr lokalisiertes Gegenstück ersetzen. Speichern Sie das Ergebnis anschließend im lokalisierten Ordner. Kein AST-Parsing, kein Markdown-Roundtripping, kein Risiko, die Formatierung zu zerschießen.
Zwei strukturelle Anpassungen müssen beim Rebuild erfolgen:
- Bildpfade. Englische Dateien referenzieren Assets mit
../../../../assets/.... Lokalisierte Dateien liegen eine Ordnerebene tiefer, daher wird der relative Pfad zu../../../../../assets/.... - Interne Links. Ein Link wie
/blog/glossary-website-translationsim Englischen muss im Französischen zu/fr/blog/glossary-website-translationswerden (und entsprechend für alle anderen Sprachen).
Hier ist der Prompt für das Skript zum Zusammenbau. Er ist generisch genug für jedes Astro-Projekt, das der Struktur aus Teil 1 folgt.
Use the unified assembly script at `scripts/assemble-blog-translations.mjs` that rebuilds
localized markdown files from an AI Glot Multi-language Columns CSV.
Inputs (CLI-Argumente):
- Pfad zur übersetzten CSV (z. B. `multilang-translation_translated.csv`)
mit den Spalten `path, English string, fr, de, es, it, pt`.
- Das Quellverzeichnis mit den englischen Original-Dateien
(Standard: `src/content/blog/live/`).
- Das Zielverzeichnis-Muster für lokalisierte Dateien
(Standard: `src/content/blog/{lang}/live/`).
- Der Website-Origin für interne Links (Standard: `https://ai-glot.com`).
Für jeden eindeutigen `path`-Wert in der CSV:
1. Lesen der englischen Originaldatei unter `<sourceDir>/<path>`.
2. Für jede Zielsprachen-Spalte (alle nach `English string`):
a. Ausgehen vom Volltext der englischen Datei.
b. Für jede Zeile, die zu diesem `path` gehört, den `English string`
wortwörtlich in der Datei suchen und durch den Wert der Zielsprachen-Spalte
ersetzen. Verwenden Sie ein literales Ersetzen, keine Regex. Fehler ausgeben,
wenn der englische Abschnitt nicht gefunden wird (das bedeutet, die Quelle
weicht von der CSV ab; dies sollte deutlich fehlschlagen statt stillschweigend zu überspringen).
c. Nach allen Ersetzungen zwei strukturelle Fixes am Text vornehmen:
- Bildpfade: Alle Vorkommen von `../../../../assets/` durch
`../../../../../assets/` ersetzen (ein zusätzliches `../`, da lokalisierte
Dateien eine Ebene tiefer liegen).
- Interne Links: Alle absoluten internen URLs dieser Seite
(z. B. `https://ai-glot.com/blog/...`) und alle wurzel-relativen Pfade
(z. B. `/blog/...`, `/sign-up`) durch die Entsprechung mit Sprach-Präfix
ersetzen (`/fr/blog/...`, `/fr/sign-up`). Anker (`#...`), externe URLs
sowie `mailto:` / `tel:` Links überspringen.
d. Datei unter `<destDir mit entsprechender Sprache>/<path>` speichern.
Verzeichnisse bei Bedarf erstellen.
3. Nach der Verarbeitung aller Pfade eine Zusammenfassung ausgeben: geschriebene
Dateien pro Sprache, Anzahl der Ersetzungen gesamt, nicht gefundene Abschnitte.
Robustheit:
- Verwenden Sie `papaparse` zum Einlesen der CSV. Entfernen Sie das BOM, falls vorhanden.
- Behalten Sie die exakte Formatierung des Frontmatters bei (Trennzeichen, Reihenfolge der Keys, Quoting).
Am einfachsten ist es, Ersetzungen direkt im Raw-String der Datei vorzunehmen, statt in einem
geparsten AST.
- Arbeiten Sie idempotent: Das mehrfache Ausführen des Skripts mit denselben Eingaben führt zu
identischen Ergebnissen.
Erstellen Sie eine einzelne, eigenständige Datei. Verwendung:
`node scripts/assemble-blog-translations.mjs translated.csv`Führen Sie das Skript aus und Sie werden sehen, wie eine Welle neuer Dateien unter src/content/blog/fr/live/, src/content/blog/de/live/ usw. erscheint. Machen Sie eine Stichprobe, führen Sie astro dev aus, und Ihre lokalisierten Routen sollten sofort gerendert werden.

Bonus 1: Eine Skill-Datei, damit jeder neue Artikel standardmäßig übersetzbar ist
Sobald die Pipeline steht, möchten Sie, dass jeder zukünftige Artikel denselben Prozess durchläuft. Der Trick: Speichern Sie diese Konvention als Skill-Datei, die Ihr KI-Assistent vor dem Schreiben eines neuen Beitrags liest.
Wenn Sie Claude Code, Cursor oder einen anderen KI-Editor nutzen, der projektbezogene Anweisungen lädt, legen Sie diese Datei als skills/blog_translation_workflow.md in Ihr Repository. Wir nutzen genau dieses Muster bei AI Glot.
---
name: blog_translation_workflow
description: How to ship a new blog post so it can be translated in bulk later.
---
# Blog-Übersetzungs-Workflow
Beachten Sie beim Schreiben neuer Blog-Posts oder CMS-Einträge diese Konventionen, damit sie reibungslos durch die mehrsprachige Extraktions-Pipeline laufen.
## 1. Speicherort und Benennung
- Entwürfe liegen unter `src/content/blog/draft/`.
- Slug = Dateiname = exakt der String aus dem `slug:` Frontmatter.
- Erst nach dem Review nach `src/content/blog/live/` verschieben.
## 2. Frontmatter-Konvention
Jeder Beitrag MUSS Folgendes enthalten:
- `title`: Sentence Case (Großschreibung nur am Satzanfang), kein Punkt am Ende.
- `metaDescription`: 140 bis 160 Zeichen, vollständiger Satz.
- `coverImage`: Relativer Pfad vom Standort dieser Datei.
- `publishedDate`: ISO-Datum.
- `slug`: Muss dem Dateinamen entsprechen.
- `faqs`: Array aus `{ question, answer }`. Mindestens 3 Einträge.
## 3. Struktur für eine gute Übersetzbarkeit
- Überschriften im Sentence Case verwenden (kein Title Case).
- Absätze auf 1 bis 4 Sätze beschränken. Da jeder Absatz zu einer CSV-Zeile wird, lassen sich kürzere Absätze zuverlässiger übersetzen.
- Niemals zwei Bilder direkt nacheinander platzieren; trennen Sie diese immer durch mindestens einen Absatz Text.
- Interne Links verwenden Root-relative Pfade (`/blog/...`, `/sign-up`).
- Bildpfade nutzen `../../../../assets/...` (die Tiefe der englischen Struktur).
## 4. Nach der Veröffentlichung
Führen Sie aus:
```bash
node scripts/extract-translations.mjs src/content/blog/live/<slug>.md \
multilang-translation.csv fr de es it pt
```
um die übersetzbaren Teile dieses Artikels an die Haupt-CSV anzuhängen. Laden Sie die CSV im Modus „Multi-language Columns“ bei AI Glot hoch und führen Sie dann aus:
```bash
node scripts/assemble-blog-translations.mjs multilang-translation_translated.csv
```
um die lokalisierten Markdown-Dateien zu generieren.
## 5. Anti-Patterns
- KEINE Gedankenstriche (Em-Dashes) verwenden; nutzen Sie Kommas oder Doppelpunkte.
- KEINE ganzen Absätze fett drucken. Nur Schlüsselbegriffe hervorheben.
- KEINEN FAQ-Bereich überspringen; FAQs sind die wirkungsvollsten SEO-Blöcke.
- KEIN rohes HTML innerhalb von Markdown verwenden, sofern nicht absolut notwendig; dies erschwert die fragmentbasierte Zusammenführung.Wenn Sie (oder jemand aus Ihrem Team) das nächste Mal einen Artikel schreiben, liest der Assistent zuerst diese Datei und erstellt einen Beitrag, der ohne manuelle Nachbearbeitung in die Pipeline passt.
Bonus 2: Eine neue Sprache für den gesamten Blog in einem einzigen Durchgang hinzufügen
Das ist der Teil, der die meisten überrascht. Sobald die Pipeline existiert, ist das Hinzufügen einer neuen Sprache für Ihr gesamtes Blog-Archiv ein einziger CSV-Vorgang.
Angenommen, Sie haben 80 Artikel ins Französische, Deutsche, Spanische, Italienische und Portugiesische übersetzt und entscheiden sich nun, Niederländisch hinzuzufügen.
Der Workflow:
- Führen Sie Ihr Extraktions-Skript erneut aus, mit
nlam Ende der Sprachenliste. Da das Skript aus dem englischen Quellordner liest, werden alle Artikel (alte und neue) einbezogen. - Öffnen Sie die CSV. Die Spalte
English stringist identisch mit dem letzten Mal. Die Spaltenfr, de, es, it, ptsind noch leer (das Skript prüft keine vorhandenen Übersetzungen, sondern erstellt lediglich die leere Matrix). Die Spaltenlist neu und leer. - Entfernen Sie die Spalten, die Sie nicht neu übersetzen müssen. Löschen Sie
fr, de, es, it, ptaus der Tabelle und behalten Siepath, English string, nl. - Laden Sie die Datei bei AI Glot hoch und nutzen Sie den „Multi-language Columns“-Modus mit
nlals einzigem Ziel. - Führen Sie das Zusammenführungs-Skript mit der neuen CSV aus. Es schreibt jeden Artikel nach
src/content/blog/nl/live/.
Sie sind in einem einzigen Upload von „Wir müssen Niederländisch hinzufügen“ zu „Niederländisch ist online“ gelangt. Für 80 Artikel. So sieht es aus, wenn der Workflow die Arbeit erledigt und nicht das Team.
Dasselbe Muster funktioniert für punktuelle Änderungen: Bearbeiten Sie einen einzelnen englischen Absatz, exportieren Sie nur die betroffenen Fragmente neu, übersetzen Sie diese und bauen Sie die Seiten neu. Updates bleiben kostengünstig, weil die Pipeline strukturell und nicht dokumentenbasiert ist.
Checkliste zur Überprüfung
Bevor Sie in die Produktion gehen, machen Sie einen kurzen Sanity-Check für jede Sprache:
npm run build(oderastro build) läuft ohneImageNotFound-Fehler durch.- Bewegen Sie den Mauszeiger über den Sprachumschalter bei einem lokalisierten Beitrag und prüfen Sie, ob die URL korrekt bleibt.
- Öffnen Sie einen französischen Beitrag und machen Sie Stichproben: Titel, Meta-Beschreibung, die ersten drei Absätze, eine FAQ-Antwort. Vergleichen Sie diese mit dem Original.
- Klicken Sie auf einen internen Link im französischen Beitrag. Er sollte Sie auf eine andere französische Seite führen, nicht zurück zum Englischen.
- Prüfen Sie den
<head>auf korrektehreflang-Annotationen über alle Sprachen hinweg. - Führen Sie ein Lighthouse-Audit für eine lokalisierte URL durch; die SEO-Bewertung sollte der englischen Version entsprechen.
Sollte einer dieser Punkte fehlschlagen, sind die häufigsten Ursachen: falsche Pfadtiefe bei Bildern, ein interner Link, der vom Regex nicht erfasst wurde, oder ein Fragment, das sich zwischen Extraktion und Zusammenführung verändert hat. Die „could not find chunk“-Warnungen des Skripts zeigen Ihnen genau, wo Sie suchen müssen.
Das Fazit
Eine mehrsprachige Astro-Seite im großen Stil ist kein Übersetzungsprojekt. Es ist eine Content-Pipeline. Wenn die Pipeline stimmt (Locale-Routing, fragmentierte CSV-Extraktion, AI Glot-Übersetzung, deterministische Zusammenführung), wird das Übersetzen eines neuen Artikels, das Korrigieren eines Absatzes oder das Hinzufügen einer Sprache zum Routinevorgang statt zum Quartalsprojekt.
Die Bausteine für den Erfolg:
- Astros integriertes i18n für saubere, sprachspezifische statische Seiten.
- Ein kleines Extraktions-Skript, das Markdown in eine übersetzbare CSV verwandelt.
- AI Glots Multi-language Columns-Modus, um alle Sprachen in einem Durchgang zu füllen – inklusive Glossar und präzisen Anweisungen.
- Ein Skript zur Zusammenführung, das die Bildtiefe und die Lokalisierung interner Links übernimmt.
- Eine Skill-Datei, damit jeder neue Artikel standardmäßig in die Pipeline passt.
Bereit für den internationalen Rollout? Erstellen Sie Ihren AI Glot Workspace, laden Sie Ihre erste Extraktions-CSV hoch und sehen Sie zu, wie Ihr Blog bis zum Ende des Nachmittags in sechs Sprachen online geht.

