
L’essentiel à retenir : un site Astro multilingue est un problème structurel avant d’être un problème de traduction. Configurez des dossiers de contenu propres par locale, extrayez chaque bloc traduisible dans un seul CSV, traduisez-le en mode Colonnes Multi-langues, puis réassemblez les fichiers par script. Une fois le pipeline en place, l’ajout d’une langue se résume à une opération sur un seul CSV.
C’est exactement le flux de travail que nous utilisons pour maintenir ai-glot.com en six langues (anglais, français, allemand, espagnol, italien, portugais) sans réécrire un seul article de blog à la main. Nous allons le détailler de bout en bout, avec les prompts que nous utilisons pour préparer chaque étape avec un assistant de code IA comme Claude Code ou Cursor.
L’objectif
À la fin de ce guide, vous disposerez de :
- Une structure de routage i18n propre dans votre projet Astro, avec un dossier par langue.
- Un script réutilisable qui extrait chaque chaîne traduisible d’un fichier markdown (ou d’un export CMS) vers un seul CSV.
- Un CSV traduit produit dans AI Glot en utilisant le mode Colonnes Multi-langues.
- Un second script qui réassemble les fichiers markdown traduits, avec les chemins d’images et les liens internes corrigés pour les sous-répertoires localisés.
- Un fichier de compétences (skill file) que vous pouvez donner à votre assistant IA pour que chaque nouvel article soit traduisible par défaut.
Si vous utilisez déjà Weglot, Crowdin ou un CMS headless qui exporte du CSV, vous pouvez sauter le script d’extraction markdown et injecter ces exports directement dans AI Glot. La logique de traduction et de réassemblage reste la même.
Prérequis
Une courte check-list avant de commencer.
- Un projet Astro (v4 ou v5) tournant en local, avec des collections de contenu configurées pour votre blog.
- Node 20 ou supérieur, pour que les API modernes CSV et
fs/promisesfonctionnent correctement. - Un espace de travail AI Glot (le compte gratuit suffit pour le premier lot).
- Un assistant IA dans votre éditeur pour générer le code de base (Claude Code, Cursor, Copilot, Codeium, selon votre préférence).
Pourquoi Astro est idéal pour le multilingue à grande échelle
Astro rend du HTML statique par défaut, ce qui signifie que chaque page localisée n’est qu’un fichier sur le disque. Il n’y a pas de couche de traduction au moment de l’exécution, pas de recherche en base de données pour le sélecteur de langue, pas de bundle JavaScript à télécharger par langue. Google indexe chaque version linguistique comme une URL distincte avec ses propres balises méta, et le résultat du build est essentiellement un miroir traduit de votre arborescence anglaise.
C’est exactement ce qu’il vous faut pour le SEO. Le SEO multilingue fonctionne mieux quand chaque langue possède sa propre page indexable et générée statiquement, avec des annotations hreflang appropriées et une structure d’URL propre. Astro vous offre cela nativement.
La contrepartie : vous êtes responsable de la synchronisation des fichiers de contenu entre les langues. C’est précisément le problème que le pipeline CSV ci-dessous vient résoudre.
Partie 1 : Configurer la structure de routage i18n
Astro 4 a introduit une configuration i18n de premier plan. Le modèle le plus propre consiste à déclarer vos langues, à définir la langue par défaut sans préfixe (pour que l’anglais reste sur /blog/mon-article et le français sur /fr/blog/mon-article), et à créer un miroir de vos collections dans un dossier [lang]/ par langue.
Voici une structure cible pour un blog en six langues :
src/
content/
blog/
live/ # English (default locale)
my-first-post.md
fr/live/ # French
my-first-post.md
de/live/ # German
my-first-post.md
es/live/ # Spanish
my-first-post.md
it/live/ # Italian
my-first-post.md
pt/live/ # Portuguese
my-first-post.md
pages/
blog/[slug].astro # English routes
[lang]/blog/[slug].astro # Localized routes
i18n/
ui.ts # UI string dictionary per localeNotez que les fichiers markdown localisés se trouvent un dossier plus profond que les fichiers anglais. Cette profondeur est importante : les chemins d’images relatifs dans le markdown localisé nécessitent un ../ supplémentaire pour atteindre src/assets/. Le script de réassemblage de la partie 4 gère cela automatiquement.
Si vous préférez ne pas écrire ce squelette vous-même, donnez le prompt suivant à votre assistant de code IA. Il est volontairement générique pour fonctionner sur n’importe quel projet Astro et pose les bonnes questions de clarification avant de générer le code.
You are helping me scaffold internationalization (i18n) in an existing Astro
project. I want to translate my entire site into multiple languages while
keeping clean URLs, proper hreflang annotations, and per-locale static pages.
Objectifs :
1. Déclarer les locales dans astro.config.mjs en utilisant l'option `i18n` intégrée.
La locale par défaut ne doit PAS être préfixée (ex: l'anglais est sur `/blog/...`,
le français sur `/fr/blog/...`).
2. Créer une structure de dossiers par langue pour mes collections de contenu afin que chaque
article de blog (ou élément CMS) ait un fichier 1:1 par langue. Les fichiers anglais
restent à leur emplacement actuel ; les fichiers localisés vivent un dossier plus bas
(ex: `src/content/blog/fr/live/`).
3. Ajouter un dictionnaire de chaînes UI typé dans `src/i18n/ui.ts` qui exporte un objet
indexé par langue, ainsi qu'un helper `useTranslations(lang)`.
4. Mettre à jour le schéma de la collection de contenu pour que la même définition Zod s'applique à
chaque dossier de langue.
5. Générer le fichier de route dynamique `src/pages/[lang]/blog/[slug].astro` qui
lit la collection de contenu localisée et revient à l'anglais si
une version localisée est manquante.
6. Ajouter un composant `<LanguageSwitcher />` qui affiche un lien par langue,
en préservant le chemin actuel.
7. Injecter des balises `<link rel="alternate" hreflang="..." />` dans le layout pour
chaque langue où la page est disponible.
Avant de générer du code, demande-moi :
- La liste des locales cibles (codes BCP 47) et laquelle est par défaut.
- Le chemin vers mes collections de contenu existantes et les fichiers de routes actuels.
- Si je veux un sélecteur de langue dans le header, le footer, ou les deux.
- Si je stocke mes chaînes UI en JSON, TS, ou ailleurs actuellement.
Ensuite, effectue les changements par petits commits précis. Ne refactorise pas de
code non lié. Montre-moi le diff et explique chaque décision lorsqu'il y a deux
modèles valides (ex: locale par défaut préfixée ou non).Ce modèle est intentionnel : clarifier, puis construire. Nous avons testé l’approche « génère tout d’un coup » au début, et nous nous sommes retrouvés avec trois composants de sélection de langue différents et un système de routage en conflit avec notre schéma de collection de contenu. Demander à l’assistant de vous interroger d’abord permet d’économiser une heure de nettoyage par la suite.
Partie 2 : Extraire votre contenu dans un CSV de traduction
C’est là que la plupart des équipes se bloquent.
C’est ici que la plupart des équipes bloquent. La traduction elle-même est la partie facile. Extraire votre contenu vers un outil de traduction et le réintégrer sans casser la structure est la partie difficile.
L’astuce qui fait briller le mode Colonnes Multi-langues d’AI Glot est l’extraction fragmentée. Vous divisez chaque fichier markdown en unités traduisibles minimales (un champ frontmatter, une question/réponse de FAQ, ou un seul paragraphe), vous écrivez chaque bloc sur une ligne de CSV, et vous ajoutez une colonne par langue cible. Le résultat ressemble à ceci :
This is where most teams get stuck. The translation itself is the easy part. Getting your content into and out of a translation tool without breaking structure is the hard part.
The trick that makes AI Glot’s Multi-language Columns mode shine is chunked extraction. You split each markdown file into the smallest meaningful translatable units (a frontmatter field, an FAQ pair, a single paragraph), write each chunk as one row in a CSV, and add one column per target language. The result looks like this:
| path | English string | fr | de | es | it | pt |
|---|---|---|---|---|---|---|
| live/my-first-post.md | How to translate an Astro website at scale into many languages | |||||
| live/my-first-post.md | A practical, copy-paste tutorial for shipping a multilingual Astro site. | |||||
| live/my-first-post.md | Astro renders static HTML by default, which means each localized page is just a file on disk. |
Pourquoi segmenter ? Parce que la traduction par IA fonctionne bien mieux sur des unités cohérentes de la taille d’un paragraphe que sur des documents entiers. Les règles du glossaire s’appliquent de manière uniforme. Les budgets de tokens restent prévisibles. Et si un segment nécessite une correction, vous modifiez une seule cellule, pas un fichier de 2 000 mots.
Option A : Vous stockez votre contenu sous forme de fichiers markdown (blog, documentation, pages de destination)
Utilisez ce prompt pour générer un script d’extraction adapté à votre dépôt. Nous utilisons une version quasi identique pour le site web d’AI Glot.
Write a Node.js script at `scripts/extract-translations.mjs` that prepares a
CSV for bulk translation in AI Glot.
Entrées :
- Un répertoire source contenant des fichiers markdown en anglais
(ex: `src/content/blog/live/`).
- Une liste de codes de langue cibles (ex: `fr de es it pt`).
- Un chemin pour le CSV de sortie (par défaut `multilang-translation.csv`).
Pour chaque fichier markdown :
1. Analysez le frontmatter à l'aide de `gray-matter`.
2. Extrayez ces chaînes traduisibles, une par ligne CSV :
- `title` (frontmatter)
- `metaDescription` (frontmatter)
- Pour chaque entrée dans `faqs` : la `question` et la `answer` sur des lignes séparées.
- Chaque paragraphe du corps du texte, en divisant le corps markdown sur `\n\n` pour que les paragraphes, les listes à puces, les citations et les titres deviennent chacun une ligne.
3. IGNOREZ ces segments (ne les incluez pas dans le CSV) :
- Les lignes contenant uniquement des images commençant par `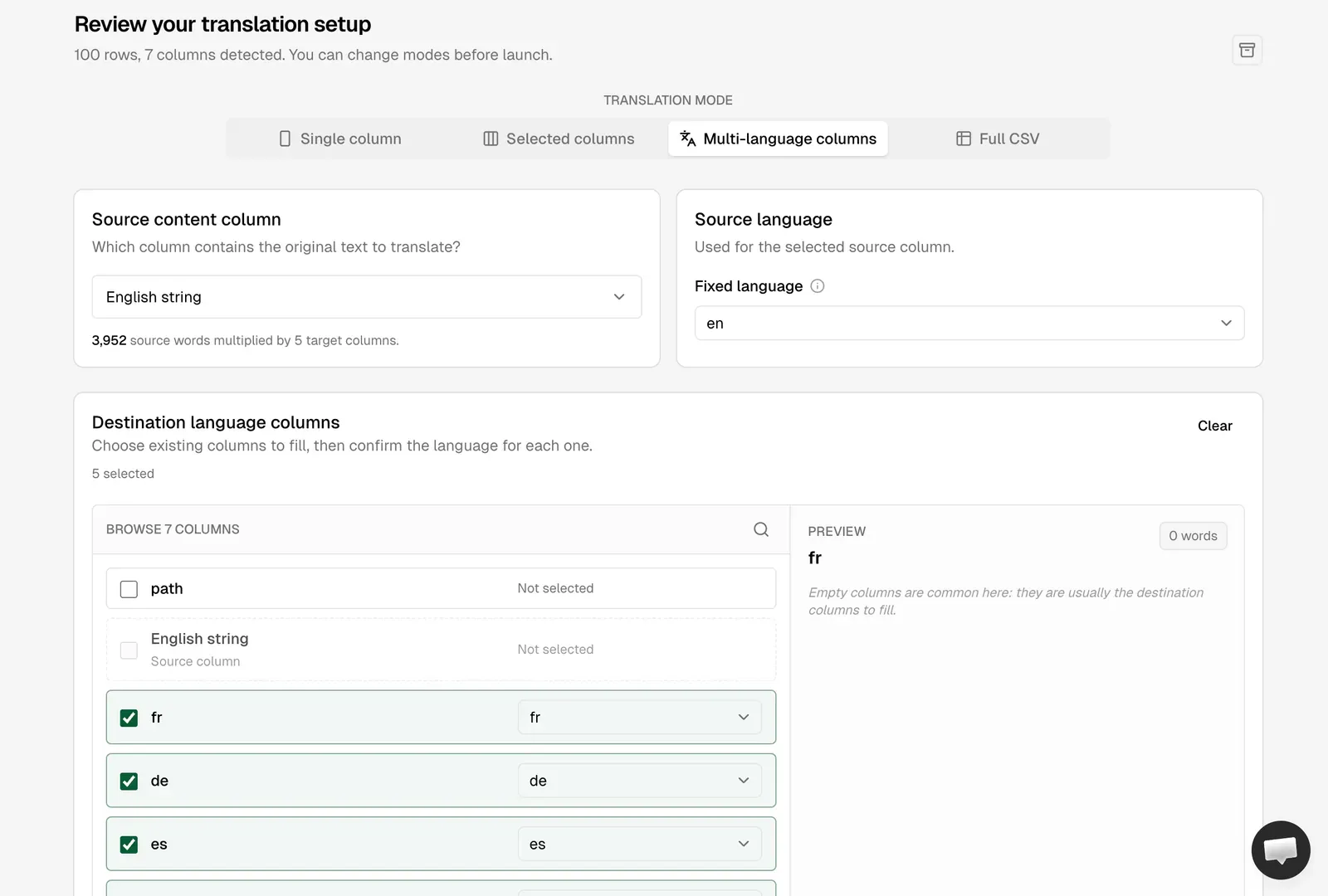
Un blog de 30 articles avec cinq langues cibles est généralement traité en quelques minutes en mode Standard, et vous pouvez passer en mode Pro pour obtenir une qualité supérieure sur les segments les plus importants (titres, méta-descriptions, paragraphes d’accroche).
Astuce : une fois le fichier téléchargé sur AI Glot, vous pouvez supprimer la version locale avec les colonnes vides. Votre espace de travail devient dès lors la source de vérité, et vous pouvez le télécharger à nouveau à tout moment.
Partie 4 : Réassembler le contenu markdown traduit dans Astro
Vous disposez maintenant d’un fichier multilang-translation_translated.csv où chaque colonne cible est remplie. La tâche consiste à reprendre chaque segment traduit et à le réinjecter dans le bon fichier markdown localisé, en préservant exactement la structure d’origine.
C’est ici que l’extraction par segments se révèle à nouveau payante. Comme chaque ligne est indexée par le segment anglais d’origine, il vous suffit de rechercher et remplacer les segments anglais par leur équivalent traduit à l’intérieur du fichier source original, puis d’enregistrer le résultat dans le dossier localisé. Pas d’analyse AST, pas de transformation complexe du markdown, aucun risque de casser le formatage.
Deux ajustements structurels doivent être effectués lors de la reconstruction :
- Chemins d’images. Les fichiers anglais font référence aux ressources avec
../../../../assets/.... Les fichiers localisés se trouvent un dossier plus bas, le chemin relatif devient donc../../../../../assets/.... - Liens internes. Un lien comme
/blog/glossary-website-translationsen anglais doit devenir/fr/blog/glossary-website-translationsen français (et ainsi de suite pour chaque langue).
Voici le prompt que nous utilisons pour générer le script de réassemblage. Il est suffisamment générique pour être intégré à n’importe quel projet Astro suivant la structure de la Partie 1.
Use the unified assembly script at `scripts/assemble-blog-translations.mjs` that rebuilds
localized markdown files from an AI Glot Multi-language Columns CSV.
Entrées (arguments CLI) :
- Chemin vers le CSV traduit (ex: `multilang-translation_translated.csv`) avec les colonnes `path, English string, fr, de, es, it, pt`.
- Le répertoire source contenant les fichiers markdown anglais originaux (par défaut `src/content/blog/live/`).
- Le modèle de répertoire de destination pour les fichiers localisés (par défaut `src/content/blog/{lang}/live/`).
- L'origine (URL) du site utilisée pour les liens internes (par défaut `https://ai-glot.com`).
Pour chaque valeur `path` unique dans le CSV :
1. Lisez le fichier anglais original depuis `<sourceDir>/<path>`.
2. Pour chaque colonne de langue cible (tout ce qui suit `English string`) :
a. Partez du texte complet du fichier anglais.
b. Pour chaque ligne correspondant à ce `path`, recherchez le `English string` textuellement dans le fichier et remplacez-le par la valeur de la colonne de la langue cible. Utilisez un remplacement de chaîne littéral, pas de regex. Générez une erreur si le segment anglais n'est pas trouvé (cela signifie que la source a divergé du CSV ; cela doit échouer explicitement plutôt que de passer sous silence).
c. Après tous les remplacements, effectuez deux corrections structurelles sur le texte résultant :
- Chemins d'images : remplacez chaque occurrence de `../../../../assets/` par `../../../../../assets/` (un `../` supplémentaire car les fichiers localisés sont un niveau plus bas).
- Liens internes : remplacez chaque URL interne absolue de ce site (ex: `https://ai-glot.com/blog/...`) et chaque chemin relatif à la racine (ex: `/blog/...`, `/sign-up`) par l'équivalent préfixé par la langue (`/fr/blog/...`, `/fr/sign-up`). Ignorez les ancres (`#...`), les URLs externes et les liens `mailto:` / `tel:`.
d. Écrivez le fichier dans `<destDir résolu avec cette langue>/<path>`. Créez les répertoires si nécessaire.
3. Après avoir traité tous les chemins, affichez un résumé : fichiers écrits par langue, total des remplacements, et tout segment n'ayant pu être trouvé.
Robustesse :
- Utilisez `papaparse` pour lire le CSV. Supprimez le BOM s'il est présent.
- Préservez exactement le formatage du frontmatter (délimiteurs, ordre des clés, guillemets).
La méthode la plus simple consiste à effectuer des remplacements sur la chaîne brute du fichier, et non sur un
AST analysé.
- Soyez idempotent : exécuter le script deux fois sur les mêmes entrées doit produire les
mêmes sorties.
Faites-en un seul fichier autonome. Utilisation :
`node scripts/assemble-blog-translations.mjs translated.csv`Lancez le script et vous verrez une vague de nouveaux fichiers apparaître sous src/content/blog/fr/live/, src/content/blog/de/live/, etc. Vérifiez-en un au hasard, lancez astro dev, et vos routes localisées devraient s’afficher instantanément.
Bonus 1 : Un fichier de « skill » pour que chaque nouvel article soit « traduisible par défaut »
Une fois que le pipeline fonctionne, vous voulez que chaque futur article y passe de la même manière. L’astuce : enregistrez la convention sous forme de fichier de « skill » que votre assistant IA lira avant d’écrire tout nouveau post.
Si vous utilisez Claude Code, Cursor ou n’importe quel éditeur IA qui charge des instructions au niveau du projet, placez ce fichier dans votre dépôt sous skills/blog_translation_workflow.md. C’est exactement ce que nous faisons chez AI Glot.
---
name: blog_translation_workflow
description: How to ship a new blog post so it can be translated in bulk later.
---
# Workflow de traduction du blog
Lors de la rédaction d'un nouvel article de blog ou d'un élément du CMS, respectez ces conventions pour qu'il
circule sans encombre dans le pipeline d'extraction multilingue.
## 1. Emplacement et nommage des fichiers
- Les brouillons se trouvent dans `src/content/blog/draft/`.
- Slug = nom du fichier = la même chaîne utilisée dans le frontmatter `slug:`.
- Déplacez vers `src/content/blog/live/` uniquement après révision.
## 2. Contrat du frontmatter
Chaque article DOIT comporter :
- `title` : casse de phrase (majuscule en début de ligne uniquement), pas de point final.
- `metaDescription` : 140 à 160 caractères, phrase complète.
- `coverImage` : chemin relatif à partir de l'emplacement du fichier.
- `publishedDate` : date au format ISO.
- `slug` : correspond au nom du fichier.
- `faqs` : tableau de `{ question, answer }`. Minimum 3 éléments.
## 3. Structure du corps pour une bonne traduction
- Utilisez des titres en casse de phrase (pas de majuscule à chaque mot).
- Limitez les paragraphes à 1 ou 4 phrases. Chaque paragraphe devient une ligne CSV,
les paragraphes courts se traduisent donc plus efficacement.
- Ne placez jamais deux images côte à côte ; séparez-les toujours par au moins un
paragraphe de texte explicatif.
- Les liens internes utilisent des chemins relatifs à la racine (`/blog/...`, `/sign-up`).
- Les chemins d'images utilisent `../../../../assets/...` (profondeur de la version anglaise).
## 4. Après la publication
Exécutez :
```bash
node scripts/extract-translations.mjs src/content/blog/live/<slug>.md \
multilang-translation.csv fr de es it pt
```
pour ajouter les segments traduisibles de cet article au CSV principal. Téléchargez le
CSV sur AI Glot en mode « Colonnes Multi-langues », puis exécutez :
```bash
node scripts/assemble-blog-translations.mjs multilang-translation_translated.csv
```
pour générer les fichiers markdown localisés.
## 5. Anti-patterns
- N'utilisez PAS de tirets cadratins (—) ; utilisez des virgules ou des deux-points.
- Ne mettez PAS de paragraphes entiers en gras. Mettez en gras uniquement les expressions clés.
- Ne faites PAS l'impasse sur la section FAQ ; les FAQ sont les blocs SEO les plus performants.
- N'insérez PAS de HTML brut dans le markdown, sauf en cas de nécessité absolue ;
cela complique la réassemblage par segments.La prochaine fois que vous (ou un membre de votre équipe) rédigerez un nouvel article, l’assistant lira d’abord ce fichier et produira un post adapté au pipeline sans nettoyage manuel.
Bonus 2 : Ajouter une nouvelle langue à l’ensemble de votre blog en un seul lot
C’est la partie qui surprend le plus les gens. Une fois le pipeline en place, l’ajout d’une nouvelle langue est une opération d’un seul CSV pour l’ensemble de vos archives.
Supposons que vous ayez 80 articles traduits en français, allemand, espagnol, italien et portugais, et que vous décidiez d’ajouter le néerlandais.
Le workflow :
- Relancez votre script d’extraction en ajoutant
nlà la liste des locales. Comme le script lit le dossier source anglais, chaque article (ancien et nouveau) est inclus. - Ouvrez le CSV. La colonne
English stringest identique à la précédente. Les colonnesfr, de, es, it, ptsont toujours vides (le script ne regarde pas les traductions existantes ; il construit juste la matrice vide). La colonnenlest nouvelle et vide. - Supprimez les colonnes que vous n’avez pas besoin de retraduire. Supprimez
fr, de, es, it, ptdu tableur, gardezpath, English string, nl. - Téléchargez sur AI Glot et lancez le mode « Colonnes Multi-langues » avec
nlcomme seule cible. - Lancez le script de réassemblage avec le nouveau CSV. Il écrit chaque article dans
src/content/blog/nl/live/.
Vous êtes passé de « nous devons ajouter le néerlandais » à « le néerlandais est en ligne » en un seul import. Pour 80 articles. C’est à cela que ça ressemble quand c’est le workflow qui travaille, pas l’équipe.
Le même modèle fonctionne pour les modifications ponctuelles : modifiez un seul paragraphe en anglais, réexportez uniquement les segments concernés, traduisez-les et reconstruisez. Les mises à jour restent peu coûteuses car le pipeline est structurel et non basé sur des documents uniques.
Liste de vérification
Avant de déployer en production, vérifiez chaque langue :
npm run build(ouastro build) réussit sans erreursImageNotFound.- Survolez le sélecteur de langue sur un article localisé et confirmez que l’URL reste propre.
- Ouvrez un article en français et vérifiez : titre, méta description, les trois premiers paragraphes, une réponse de FAQ. Comparez avec la source.
- Cliquez sur un lien interne dans l’article français. Il devrait vous mener vers une autre page en français, pas vers la version anglaise.
- Inspectez le
<head>pour vérifier les annotationshreflangsur toutes les langues. - Lancez un audit Lighthouse sur une URL localisée ; le score SEO doit être identique à l’équivalent anglais.
En cas d’échec, les coupables les plus fréquents sont : une mauvaise profondeur de chemin d’image, un lien interne qui a échappé à la regex, ou un segment qui a dévié entre l’extraction et le réassemblage. Les avertissements « could not find chunk » du script de réassemblage vous indiquent exactement où regarder.
Ce qu’il faut retenir
Un site Astro multilingue à grande échelle n’est pas un projet de traduction. C’est un pipeline de contenu. Si vous configurez correctement le pipeline (routage par langue, extraction de segments en CSV, traduction via AI Glot, réassemblage déterministe), traduire un nouvel article, corriger un paragraphe ou ajouter une langue devient une opération de routine plutôt qu’une initiative trimestrielle.
Les pièces maîtresses du système :
- L’i18n native d’Astro pour des pages statiques propres par langue.
- Un petit script d’extraction qui transforme le markdown en CSV traduisible.
- Le mode Colonnes Multi-langues d’AI Glot pour remplir toutes les langues en un seul passage, avec contrôle du glossaire et des instructions.
- Un script de réassemblage qui gère la profondeur des images et la localisation des liens internes.
- Un fichier de « skill » pour que chaque nouvel article s’intègre par défaut au pipeline.
Prêt pour le multilingue ? Créez votre espace de travail AI Glot, téléchargez votre premier CSV d’extraction et regardez votre blog passer en six langues d’ici la fin de l’après-midi.

