
Resumo da ópera: um site Astro multilíngue é um problema estrutural antes de ser um problema de tradução. Configure pastas de conteúdo limpas por localidade, extraia cada trecho traduzível em um CSV, traduza-o no modo Multi-language Columns e, em seguida, remonte os arquivos programaticamente. Uma vez que o fluxo está pronto, adicionar um novo idioma torna-se uma operação de um único CSV.
Este é exatamente o fluxo de trabalho que usamos para manter o ai-glot.com em seis idiomas (inglês, francês, alemão, espanhol, italiano e português) sem reescrever um único post manualmente. Vamos percorrer o processo de ponta a ponta, com os comandos (prompts) que usamos para estruturar cada etapa com um assistente de codificação de IA como o Claude Code ou o Cursor.
O objetivo
Ao final deste guia, você terá:
- Uma estrutura limpa de roteamento i18n no seu projeto Astro, com uma pasta por idioma.
- Um script reutilizável que extrai todas as strings traduzíveis de um arquivo markdown (ou de uma exportação de CMS) para um único CSV.
- Um CSV traduzido produzido no AI Glot usando o modo Multi-language Columns.
- Um segundo script que remonta os arquivos markdown traduzidos, com caminhos de imagem e links internos corrigidos para os subdiretórios localizados.
- Um arquivo de contexto (skill file) que você pode entregar ao seu assistente de IA para que cada novo artigo já nasça pronto para tradução por padrão.
Se você já utiliza Weglot, Crowdin ou um CMS headless que exporta CSV, pode pular o script de extração de markdown e enviar essas exportações diretamente para o AI Glot. A lógica de tradução e remontagem é a mesma.
Pré-requisitos
Um rápido checklist antes de começar.
- Um projeto Astro (v4 ou v5) rodando localmente, com coleções de conteúdo (content collections) configuradas para o seu blog.
- Node 20 ou superior, para que as APIs modernas de CSV e
fs/promisesfuncionem sem problemas. - Um espaço de trabalho no AI Glot (o plano gratuito é suficiente para o primeiro lote).
- Um assistente de IA no seu editor para gerar o código base (Claude Code, Cursor, Copilot, Codeium — escolha o seu preferido).
Por que o Astro é perfeito para escala multilíngue
O Astro renderiza HTML estático por padrão, o que significa que cada página localizada é apenas um arquivo no disco. Não há camada de tradução em tempo de execução, nem consulta a banco de dados para troca de idioma, nem pacote de JavaScript extra para baixar por localidade. O Google indexa cada versão de idioma como uma URL distinta com suas próprias meta tags, e o resultado do build é essencialmente um espelho traduzido da sua árvore em inglês.
Isso é exatamente o que você quer para SEO. O SEO multilíngue funciona melhor quando cada idioma tem sua própria página rastreável e gerada estaticamente, com anotações hreflang adequadas e uma estrutura de URL limpa. O Astro oferece isso nativamente.
O contraponto: você é responsável por manter os arquivos de conteúdo sincronizados entre os idiomas. É precisamente esse o problema que o fluxo de CSV abaixo resolve.
Parte 1: Configurar a estrutura de roteamento i18n
O Astro 4 introduziu uma configuração de i18n de primeira classe. O padrão mais limpo é declarar seus idiomas, definir o padrão para sem prefixo (para que o inglês fique em /blog/meu-post e o francês em /fr/blog/meu-post) e espelhar suas coleções de conteúdo em uma pasta [lang]/ por idioma.
Aqui está uma estrutura de exemplo para um blog com seis idiomas:
src/
content/
blog/
live/ # English (default locale)
my-first-post.md
fr/live/ # French
my-first-post.md
de/live/ # German
my-first-post.md
es/live/ # Spanish
my-first-post.md
it/live/ # Italian
my-first-post.md
pt/live/ # Portuguese
my-first-post.md
pages/
blog/[slug].astro # English routes
[lang]/blog/[slug].astro # Localized routes
i18n/
ui.ts # UI string dictionary per localeObserve que os arquivos markdown localizados ficam uma pasta abaixo dos arquivos em inglês. Essa profundidade é importante: caminhos de imagem relativos no markdown localizado precisam de um ../ extra para alcançar src/assets/. O script de remontagem na Parte 4 lida com isso automaticamente.
Se preferir não escrever essa estrutura manualmente, entregue o seguinte prompt ao seu assistente de IA. Ele é intencionalmente genérico para funcionar em qualquer projeto Astro e faz as perguntas certas antes de gerar o código.
You are helping me scaffold internationalization (i18n) in an existing Astro
project. I want to translate my entire site into multiple languages while
keeping clean URLs, proper hreflang annotations, and per-locale static pages.
Objetivos:
1. Declarar os idiomas no astro.config.mjs usando a opção nativa `i18n`.
O idioma padrão NÃO deve ter prefixo (ex: inglês fica em `/blog/...`,
francês em `/fr/blog/...`).
2. Criar uma estrutura de pastas por idioma para minhas coleções de conteúdo
para que cada post (ou item de CMS) tenha um arquivo 1:1 por idioma. Os
arquivos em inglês permanecem no local atual; os arquivos localizados ficam
uma pasta abaixo (ex: `src/content/blog/fr/live/`).
3. Adicionar um dicionário de strings de UI tipado em `src/i18n/ui.ts` que exporta
um objeto por idioma, além de um helper `useTranslations(lang)`.
4. Atualizar o esquema da coleção de conteúdo para que a mesma definição Zod se
aplique a todas as pastas de idioma.
5. Gerar o arquivo de rota dinâmica `src/pages/[lang]/blog/[slug].astro` que lê
da coleção de conteúdo localizada e usa o inglês como fallback quando uma
versão localizada estiver ausente.
6. Adicionar um componente `<LanguageSwitcher />` que renderiza um link por idioma,
preservando o caminho (pathname) atual.
7. Injetar tags `<link rel="alternate" hreflang="..." />` no layout para cada
idioma que tenha a página disponível.
Antes de gerar qualquer código, pergunte-me:
- A lista de idiomas de destino (códigos BCP 47) e qual é o padrão.
- O caminho para minha(s) coleção(ões) de conteúdo e arquivos de rota atuais.
- Se eu quero o seletor de idiomas no cabeçalho, rodapé ou ambos.
- Se eu armazeno strings de UI em JSON, TS ou outro lugar atualmente.
Em seguida, faça as alterações em commits pequenos e cirúrgicos. Não refatore
código não relacionado. Mostre-me o diff e explique qualquer decisão onde houver
dois padrões válidos (ex: idioma padrão prefixado vs. não prefixado).Este padrão é intencional: esclarecer antes de construir. Tentamos a abordagem de “apenas gerar tudo” no início e acabamos com três componentes de troca de idioma diferentes e um esquema de roteamento que conflitou com nosso esquema de coleção de conteúdo. Pedir para o assistente perguntar antes economiza uma hora de limpeza depois.
Parte 2: Extrair seu conteúdo para um CSV de tradução
É aqui que a maioria das equipes fica travada.
É aqui que a maioria das equipes trava. A tradução em si é a parte fácil. Colocar seu conteúdo dentro e fora de uma ferramenta de tradução sem quebrar a estrutura é a parte difícil.
O truque que faz o modo Multi-language Columns do AI Glot brilhar é a extração fragmentada (chunked extraction). Você divide cada arquivo markdown nas menores unidades traduzíveis significativas (um campo de frontmatter, um par de FAQ, um único parágrafo), escreve cada trecho como uma linha em um CSV e adiciona uma coluna por idioma de destino. O resultado se parece com isto:
This is where most teams get stuck. The translation itself is the easy part. Getting your content into and out of a translation tool without breaking structure is the hard part.
The trick that makes AI Glot’s Multi-language Columns mode shine is chunked extraction. You split each markdown file into the smallest meaningful translatable units (a frontmatter field, an FAQ pair, a single paragraph), write each chunk as one row in a CSV, and add one column per target language. The result looks like this:
| path | English string | fr | de | es | it | pt |
|---|---|---|---|---|---|---|
| live/my-first-post.md | Como traduzir um site Astro em escala para vários idiomas | |||||
| live/my-first-post.md | Um tutorial prático de copiar e colar para lançar um site Astro multilíngue. | |||||
| live/my-first-post.md | O Astro renderiza HTML estático por padrão, o que significa que cada página localizada é apenas um arquivo no disco. |

Por que segmentar?
Por que de forma fragmentada? Porque a tradução por IA funciona muito melhor em unidades coerentes do tamanho de parágrafos do que em documentos inteiros. As regras do glossário são aplicadas de forma consistente. Os orçamentos de tokens permanecem previsíveis. E se um fragmento precisar de correção, você edita uma célula, não um arquivo de 2.000 palavras.
Opção A: Você armazena conteúdo como arquivos markdown (blog, docs, landing pages)
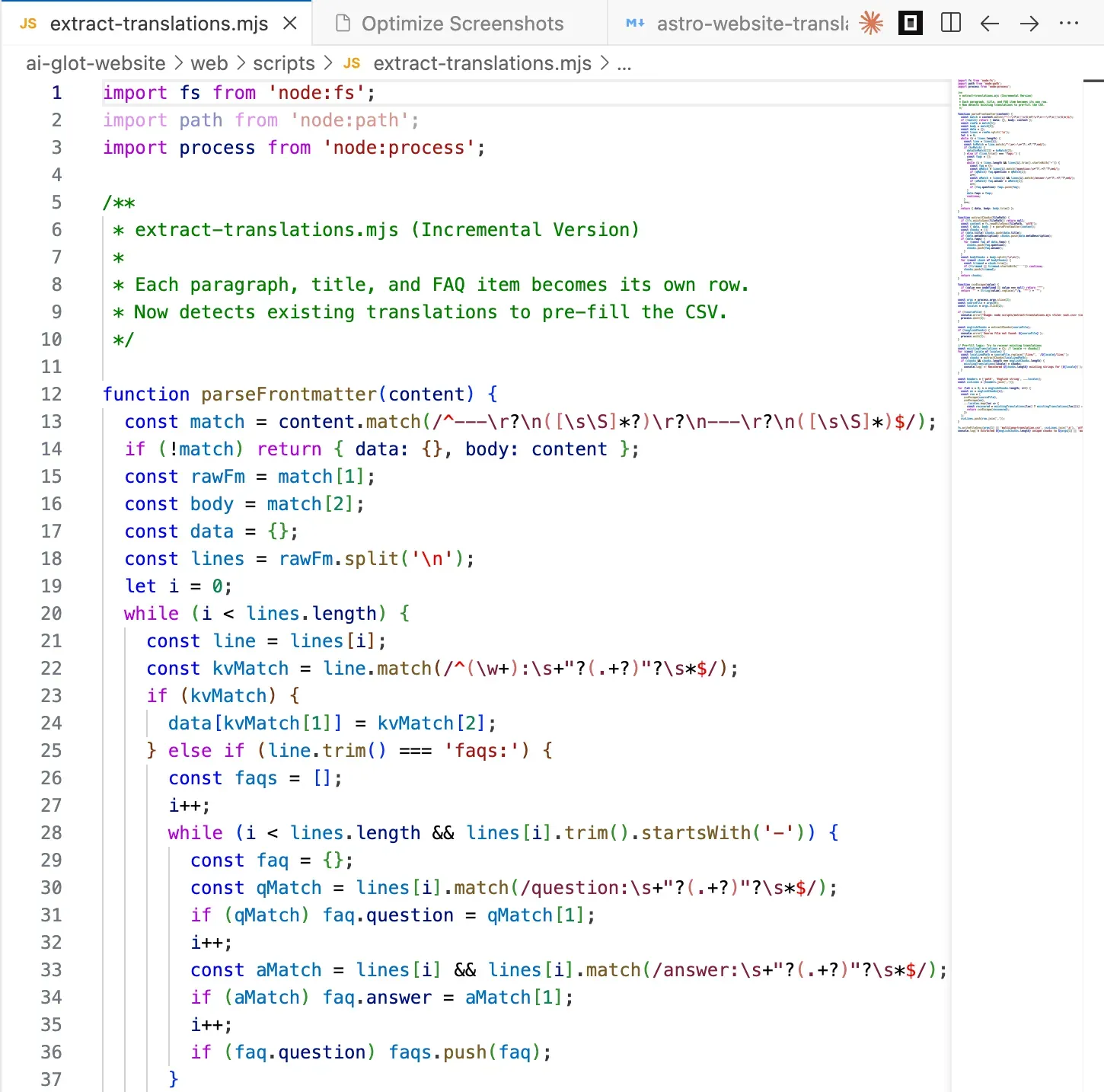
Use este prompt para gerar um script de extração adaptado ao seu repositório. Usamos uma versão quase idêntica para o site da AI Glot.
Write a Node.js script at `scripts/extract-translations.mjs` that prepares a
CSV for bulk translation in AI Glot.
Entradas:
- Um diretório de origem contendo arquivos markdown em inglês
(ex: `src/content/blog/live/`).
- Uma lista de códigos de idiomas de destino (ex: `fr de es it pt`).
- Um caminho para o CSV de saída (padrão `multilang-translation.csv`).
Para cada arquivo markdown:
1. Analise o frontmatter usando `gray-matter`.
2. Extraia estas strings traduzíveis, uma por linha do CSV:
- `title` (frontmatter)
- `metaDescription` (frontmatter)
- Para cada entrada em `faqs`: a `question` (pergunta) e a `answer` (resposta) como linhas separadas.
- Cada parágrafo do corpo, dividindo o corpo do markdown em `\n\n` para que parágrafos,
listas com marcadores, blocos de citação e cabeçalhos se tornem, cada um, uma linha.
3. PULE estes fragmentos (não os inclua no CSV):
- Linhas de imagem pura que começam com `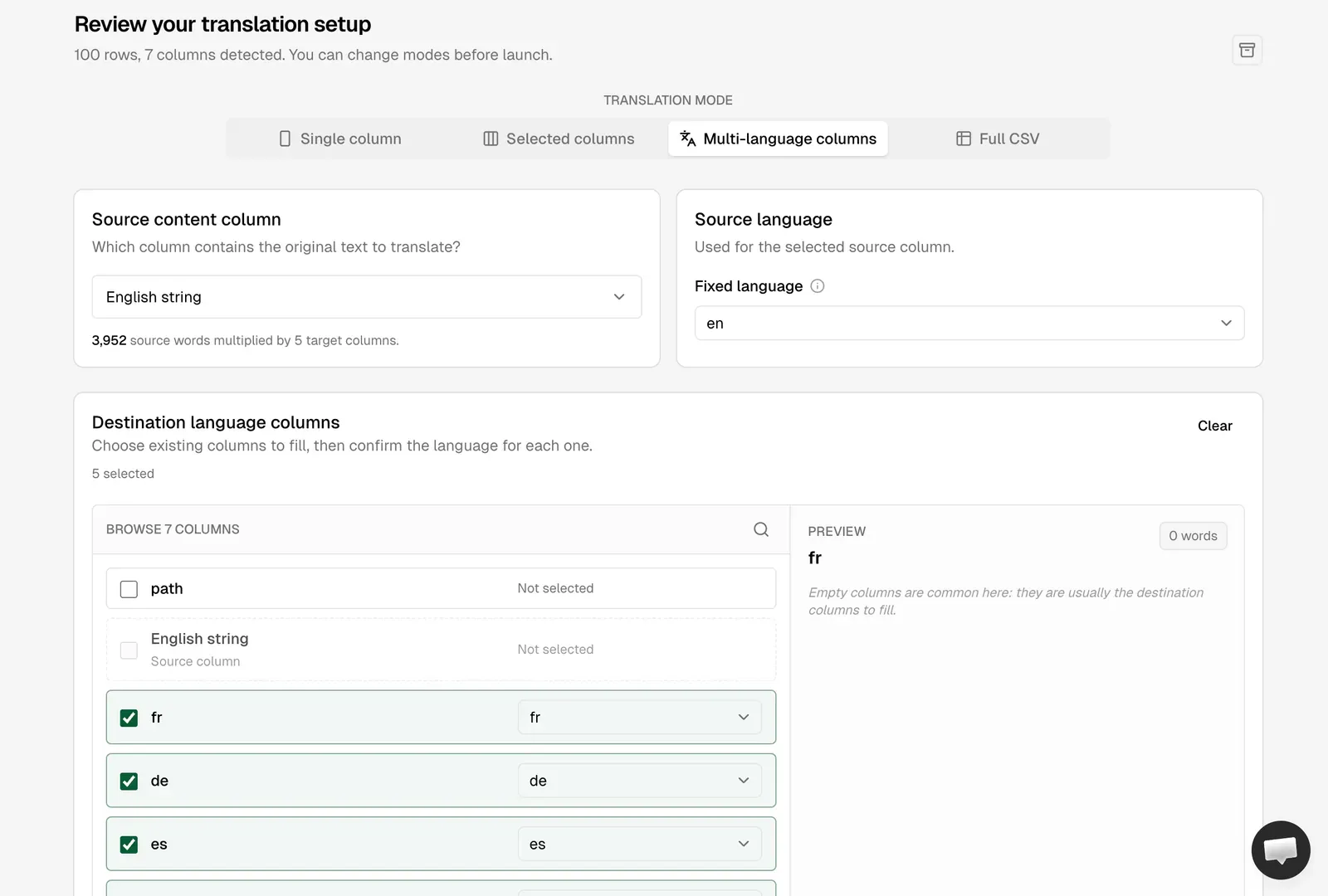
Um blog com 30 posts e cinco idiomas de destino é normalmente processado em poucos minutos no modo Standard, e você pode mudar para o modo Pro para obter resultados de maior qualidade nas linhas que mais importam (títulos, meta descrições, parágrafos de destaque).
Dica: assim que o arquivo for carregado na AI Glot, você pode excluir a versão local de colunas vazias. Seu workspace passa a ser a fonte da verdade a partir desse momento e você sempre poderá baixá-lo novamente.
Parte 4: Remonte o markdown traduzido de volta no Astro
Agora você tem um multilang-translation_translated.csv com todas as colunas de destino preenchidas. O trabalho agora é pegar cada fragmento traduzido e gravá-lo de volta no arquivo markdown localizado correto, preservando exatamente a estrutura original.
É aqui que a extração fragmentada se paga novamente. Como cada linha é identificada pelo fragmento original em inglês, você pode simplesmente localizar e substituir os fragmentos em inglês por sua contraparte localizada dentro do arquivo original, e então salvar o resultado na pasta localizada. Sem análise de AST, sem conversões complexas de markdown, sem risco de quebrar a formatação.
Duas correções estruturais precisam acontecer durante a remontagem:
- Caminhos de imagem. Arquivos em inglês referenciam ativos com
../../../../assets/.... Arquivos localizados ficam em uma pasta mais profunda, então o caminho relativo torna-se../../../../../assets/.... - Links internos. Um link como
/blog/glossary-website-translationsem inglês precisa se tornar/pt/blog/glossary-website-translationsem português (e assim por diante para cada idioma).
Aqui está o prompt que usamos para gerar o script de remontagem. Ele é genérico o suficiente para ser usado em qualquer projeto Astro que siga a estrutura da Parte 1.
Use the unified assembly script at `scripts/assemble-blog-translations.mjs` that rebuilds
localized markdown files from an AI Glot Multi-language Columns CSV.
Entradas (parâmetros de CLI):
- Caminho para o CSV traduzido (ex: `multilang-translation_translated.csv`)
com as colunas `path, English string, fr, de, es, it, pt`.
- O diretório de origem que contém os arquivos markdown originais em inglês
(padrão `src/content/blog/live/`).
- O padrão do diretório de destino para arquivos localizados
(padrão `src/content/blog/{lang}/live/`).
- A origem (origin) do site usada para links internos (padrão `https://ai-glot.com`).
Para cada valor único de `path` no CSV:
1. Leia o arquivo original em inglês de `<sourceDir>/<path>`.
2. Para cada coluna de idioma de destino (tudo após `English string`):
a. Comece a partir do texto completo do arquivo em inglês.
b. Para cada linha que corresponda a este `path`, encontre a `English string`
literalmente no arquivo e substitua-a pelo valor na coluna do idioma
de destino. Use substituição de string literal, não regex. Lance um erro
se o fragmento em inglês não for encontrado (isso indica divergência entre
a origem e o CSV; o erro deve ser explícito em vez de ignorar silenciosamente).
c. Após todas as substituições, execute duas correções estruturais no texto resultante:
- Caminhos de imagem: substitua cada ocorrência de `../../../../assets/` por
`../../../../../assets/` (um `../` extra porque os arquivos localizados ficam
um nível abaixo).
- Links internos: substitua cada URL interna absoluta neste site
(ex: `https://ai-glot.com/blog/...`) e cada caminho relativo à raiz
(ex: `/blog/...`, `/sign-up`) pelo equivalente com o prefixo do idioma
(`/pt/blog/...`, `/pt/sign-up`). Pule âncoras (`#...`), URLs externas
e links `mailto:` / `tel:`.
d. Grave o arquivo em `<destDir resolvido com este idioma>/<path>`. Crie
diretórios conforme necessário.
3. Após processar todos os caminhos, exiba um resumo: arquivos gravados por idioma,
total de substituições e quaisquer fragmentos que não foram encontrados.
Robustez:
- Use `papaparse` para ler o CSV. Remova o BOM, se estiver presente.
- Preserve a formatação exata do frontmatter (delimitadores, ordem das chaves, aspas).
A maneira mais simples é fazer substituições na string bruta do arquivo, e não num
AST analisado.
- Seja idempotente: rodar o script duas vezes com os mesmos inputs produz os
mesmos resultados.
Crie um arquivo único e independente. Uso:
`node scripts/assemble-blog-translations.mjs translated.csv`Execute o script e você verá uma onda de novos arquivos surgirem em src/content/blog/fr/live/, src/content/blog/de/live/, e assim por diante. Faça uma verificação rápida em um deles, execute astro dev, e suas rotas localizadas deverão renderizar na hora.
Bônus 1: Um arquivo de “skill” para que cada novo artigo seja “traduzível por padrão”
Assim que o pipeline estiver funcionando, você vai querer que todos os artigos futuros fluam por ele da mesma forma. O truque: armazene a convenção como um arquivo de skill que seu assistente de IA lê antes de escrever qualquer novo post.
Se você usa Claude Code, Cursor ou qualquer editor de IA que carregue instruções ao nível do projeto, coloque este arquivo no seu repositório como skills/blog_translation_workflow.md. Usamos exatamente esse padrão na AI Glot.
---
name: blog_translation_workflow
description: How to ship a new blog post so it can be translated in bulk later.
---
# Fluxo de trabalho de tradução do blog
Ao escrever um novo post no blog ou item do CMS, siga estas convenções para que ele
flua perfeitamente pelo pipeline de extração multilíngue.
## 1. Localização e nomenclatura dos arquivos
- Os rascunhos ficam em `src/content/blog/draft/`.
- Slug = nome do arquivo = a mesma string usada no frontmatter `slug:`.
- Mova para `src/content/blog/live/` apenas após a revisão.
## 2. Contrato do frontmatter
Todo post DEVE ter:
- `title`: apenas a primeira letra da frase em maiúscula, sem ponto final.
- `metaDescription`: 140 a 160 caracteres, frase completa.
- `coverImage`: caminho relativo a partir da localização deste arquivo.
- `publishedDate`: data em formato ISO.
- `slug`: deve coincidir com o nome do arquivo.
- `faqs`: array de `{ question, answer }`. Mínimo de 3 itens.
## 3. Estrutura de corpo que traduz bem
- Use títulos com apenas a primeira letra em maiúscula (evite Title Case).
- Mantenha os parágrafos de 1 a 4 frases. Cada parágrafo torna-se uma linha no CSV,
portanto, parágrafos curtos traduzem com mais confiabilidade.
- Nunca coloque duas imagens seguidas; sempre as separe com pelo menos um
parágrafo de texto explicativo.
- Links internos usam caminhos relativos à raiz (`/blog/...`, `/sign-up`).
- Caminhos de imagem usam `../../../../assets/...` (profundidade do idioma original).
## 4. Após a publicação
Execute:
```bash
node scripts/extract-translations.mjs src/content/blog/live/<slug>.md \
multilang-translation.csv fr de es it pt
```
para anexar os trechos traduzíveis deste artigo ao CSV mestre. Suba o
CSV para a AI Glot no modo "Multi-language Columns", depois execute:
```bash
node scripts/assemble-blog-translations.mjs multilang-translation_translated.csv
```
para gerar os arquivos markdown localizados.
## 5. Anti-padrões
- NÃO use travessões (em-dashes); use vírgulas ou dois-pontos.
- NÃO coloque parágrafos inteiros em negrito. Destaque apenas frases-chave.
- NÃO pule a seção de FAQ; FAQs são blocos de SEO com altíssimo impacto.
- NÃO insira HTML bruto diretamente no markdown, a menos que seja estritamente necessário;
isso dificulta a remontagem baseada em blocos.Na próxima vez que você (ou qualquer pessoa da sua equipe) escrever um novo artigo, o assistente lerá este arquivo primeiro e produzirá um post que se ajusta ao pipeline sem a necessidade de ajustes manuais.
Bônus 2: Adicionando um novo idioma a todo o seu blog de uma só vez
Esta é a parte que mais surpreende as pessoas. Uma vez que o pipeline existe, adicionar um novo idioma é uma operação de um único CSV em todo o arquivo do seu blog.
Digamos que você tenha 80 artigos traduzidos para francês, alemão, espanhol, italiano e português, e decida adicionar o holandês.
O fluxo de trabalho:
- Execute novamente seu script de extração acrescentando
nlà lista de idiomas. Como o script lê a pasta de origem em inglês, todos os artigos (antigos e novos) são incluídos. - Abra o CSV. A coluna
English stringé idêntica à da última vez. As colunasfr, de, es, it, ptainda estão vazias (o script não olha para traduções existentes; ele apenas constrói a matriz vazia). A colunanlé nova e está vazia. - Remova as colunas que você não precisa retraduzir. Delete
fr, de, es, it, ptda planilha, mantenhapath, English string, nl. - Faça o upload para a AI Glot e execute o modo “Multi-language Columns” com
nlcomo o único alvo. - Execute o script de remontagem com o novo CSV. Ele escreverá cada artigo em
src/content/blog/nl/live/.
Você passou de “precisamos adicionar holandês” para “holandês publicado” em apenas um upload. Para 80 artigos. É assim que fica quando o fluxo de trabalho faz o serviço, não a equipe.
O mesmo padrão funciona para alterações pontuais: edite um único parágrafo em inglês, re-exporte apenas os trechos afetados, traduza-os e reconstrua. As atualizações continuam baratas porque o pipeline é estrutural, não baseado em documentos.
Checklist de verificação
Antes de fazer o push para produção, faça um teste de sanidade em cada idioma:
npm run build(ouastro build) deve ser concluído sem erros deImageNotFound.- Passe o mouse sobre o seletor de idiomas em um post localizado e confirme se a URL permanece limpa.
- Abra um post em francês e verifique: título, meta description, três primeiros parágrafos e uma resposta de FAQ. Compare com o original.
- Clique em um link interno dentro do post em francês. Ele deve te levar para outra página em francês, não de volta para o inglês.
- Inspecione o
<head>para garantir as anotaçõeshreflangcorretas em todos os idiomas. - Execute uma auditoria do Lighthouse em uma URL localizada; a pontuação de SEO deve ser a mesma da equivalente em inglês.
Se algum desses falhar, os culpados mais comuns são: profundidade incorreta do caminho da imagem, um link interno que escapou do regex ou um trecho que se perdeu entre a extração e a remontagem. Os avisos de “could not find chunk” do script de remontagem indicam exatamente onde procurar.
Conclusão
Um site Astro multilíngue em escala não é um projeto de tradução. É um pipeline de conteúdo. Acerte o pipeline (roteamento por idioma, extração de CSV em blocos, tradução via AI Glot, remontagem determinística) e traduzir um novo artigo, corrigir um parágrafo ou adicionar um novo idioma torna-se uma operação de rotina, em vez de uma iniciativa trimestral.
As peças que fazem isso funcionar:
- i18n nativo do Astro para páginas estáticas limpas por idioma.
- Um pequeno script de extração que transforma markdown em um CSV traduzível.
- Modo de Colunas Multilíngues da AI Glot para preencher todos os idiomas em uma única passagem, com controle de glossário e instruções.
- Um script de remontagem que lida com a profundidade das imagens e a localização de links internos.
- Um arquivo de skill para que cada novo artigo se ajuste ao pipeline por padrão.
Pronto para publicar em vários idiomas? Crie seu workspace na AI Glot, envie seu primeiro CSV de extração e veja seu blog entrar no ar em seis idiomas até o fim da tarde.


